Football ETL Analysis P2
Source
Hello! Hello! OG đây, sau phần 1 chúng ta đã setup các kiểu và đảm bảo mọi thứ trơn tru rồi, ở phần này chúng ta sẽ chuẩn bị Data Source, và khởi chạy pipeline ở Implement sau đó sẽ Visualize cleaned data có được từ data warehouse thành Dashboard.
Bắt đầu thôi nào !
Data Source
Chuẩn bị file làm raw data
Các file csv sử dụng làm dữ liệu được tải từ Football Database - Kaggle. Đây là dữ liệu thống kê của cầu thủ, đội bóng đến từ 5 giải bóng hàng đầu Châu Âu (Premier League, Laliga, Seria A, Budesliga, League 1)
Ta sẽ có schema như sau:

Schema
trong đó:
games: bảng chứa thông tin thống kê của từng trận đấu (gameID)teams: Bảng chứa tên các đội bóng (teamID)players: Bảng chứa tên các cầu thủ (playerID)leagues: Bảng chưa tên các giải đấu (leagueID)appearances: Bảng thống kê của cầu thủ ở các game mà họ tham gia (gameID, playerID)teamstats: Bảng thống kê của đội bóng ở từng game (gameID, teamID)
Load data vào MySQL
Có nhiều cách để load data vào MySQL, ở đây mình sẽ sử dụng cách LOAD LOCAL_INFILE của MySQL luôn.
make up lần đầu rồi nhé !Hãy copy folder chứa các file csv vào de_mysql container:
docker cp /football de_mysql:/tmp/dataset/
docker cp /load_data de_mysql:/tmp/dataset/Sau đó tạo bảng trống sẵn trong MySQL:
make mysql_create #Create table in mysqlTiếp tục với lệnh:
make to_mysql_root
# ----- You will access to MySQL container
SET GLOBAL LOCAL_INFILE=TRUE; #Set local_infile variable to load data from local
exit;
# ----- Exit container
make mysql_load #load data
make mysql_create_relation #create table relationThế là đã chuẩn bị xong dữ liệu cho MySQL.
Init PostgreSQL Schema
Ta cũng cần phải tạo sẵn schema sẵn trong Posgres như sau:
make to_psql
CREATE SCHEMA IF NOT EXISTS analysis;
exit;Thế là đã hoàn tất việc chuẩn bị data, giờ thì ta bắt đầu vào phần việc chính thôi
Implement
Công việc chính trong phần này là xây dựng các data pipeline bằng dagster. Cơ bản có thể hiểu là ta tạo các Asset và chuyển chúng từ database này sang database khác.
Extraction
Để có thể quản lý việc truy xuất dữ liệu từ MySQL và load vào MinIO để lưu tạm, ta sẽ xây dựng một I/O Manager phục vụ việc đó.
Đầu tiên, hãy vào đường dẫn: ./etl_pipeline/etl_pipeline/resources/
Ta sẽ xây dựng MySQL io manager bằng cách tạo file mysql_io_manager.py với nội dung sau:
from contextlib import contextmanager
from datetime import datetime
import pandas as pd
from dagster import IOManager, OutputContext, InputContext
from sqlalchemy import create_engine
@contextmanager
def connect_mysql(config):
conn_info = (
f"mysql+pymysql://{config['user']}:{config['password']}" + f"@{config['host']}:{config['port']}" + f"/{config['database']}"
)
db_conn = create_engine(conn_info)
try:
yield db_conn
except Exception:
raise
class MySQLIOManager(IOManager):
def __init__(self, config):
self.config = config
def handle_output(self, context: OutputContext, obj: pd.DataFrame):
pass
def load_input(self, context: InputContext) -> pd.DataFrame:
pass
def extract_data(self, sql: str) -> pd.DataFrame:
with connect_mysql(self.config) as db_conn:
pd_data = pd.read_sql_query(sql, db_conn)
return pd_dataSau đó, tiếp tục đối với minio_io_manager.py:
import os
from contextlib import contextmanager
from datetime import datetime
from typing import Union
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
from dagster import IOManager, InputContext, OutputContext
from minio import Minio
@contextmanager
def connect_minio(config):
client = Minio(
endpoint=config.get("endpoint_url"),
access_key=config.get("aws_access_key_id"),
secret_key=config.get("aws_secret_access_key"),
secure=False
)
try:
yield client
except Exception:
raise
class MinIOIOManager(IOManager):
def __init__(self, config):
self._config= config
def _get_path(self, context: Union[InputContext, OutputContext]):
layer, schema, table = context.asset_key.path
key = "/".join([layer, schema, table.replace(f"{layer}_", "")])
tmp_file_path = "/tmp/file-{}-{}.parquet".format(
datetime.today().strftime("%Y%m%d%H%M%S"),
"-".join(context.asset_key.path)
)
if context.has_asset_partitions:
start, end = context.asset_partitions_time_window
dt_format = "%Y%m%d%H%M%S"
partition_str = start.strftime(dt_format) + "_" + end.strftime(dt_format)
return os.path.join(key, f"{partition_str}.pq"), tmp_file_path
else:
return f"{key}.pq", tmp_file_path
def handle_output(self, context: OutputContext, obj: pd.DataFrame):
# convert to parquet format
key_name, tmp_file_path = self._get_path(context)
table = pa.Table.from_pandas(obj)
pq.write_table(table, tmp_file_path)
# upload to MinIO
try:
bucket_name = self._config.get("bucket")
with connect_minio(self._config) as client:
# Make bucket if not exist.
found = client.bucket_exists(bucket_name)
if not found:
client.make_bucket(bucket_name)
else:
print(f"Bucket {bucket_name} already exists")
client.fput_object(bucket_name, key_name, tmp_file_path)
row_count = len(obj)
context.add_output_metadata({"path": key_name, "tmp": tmp_file_path})
# clean up tmp file
os.remove(tmp_file_path)
except Exception:
raise
def load_input(self, context: InputContext) -> pd.DataFrame:
bucket_name = self._config.get("bucket")
key_name, tmp_file_path = self._get_path(context)
try:
with connect_minio(self._config) as client:
#Make bucket if not exist
found = client.bucket_exists(bucket_name)
if not found:
client.make_bucket(bucket_name)
else:
print(f"Bucket {bucket_name} already exist")
client.fget_object(bucket_name, key_name, tmp_file_path)
pd_data = pd.read_parquet(tmp_file_path)
return pd_data
except Exception:
raiseSau khi đã tạo thành công các io manager cho mysql và minio, ta sẽ bắt đầu xây dựng bronze layer
Trong project này mình chia các giai đoạn transformation thành các layer:
bronze layer: Giai đoạn chỏ mới load raw data, có thể hiểu đây là data chưa transform gì cảsiler layer: Transform một phần từ bronze layer, ở đoạn này data đã được cleaning sơgold layer: Sau khi transform một lần nữa từ silver layer, giai đoạn này sẽ truy vấn ra các thông tin hữu ích nhất để phân tích và data hoàn toàn sạch sẽ sẵn sàng được load vào warehouse
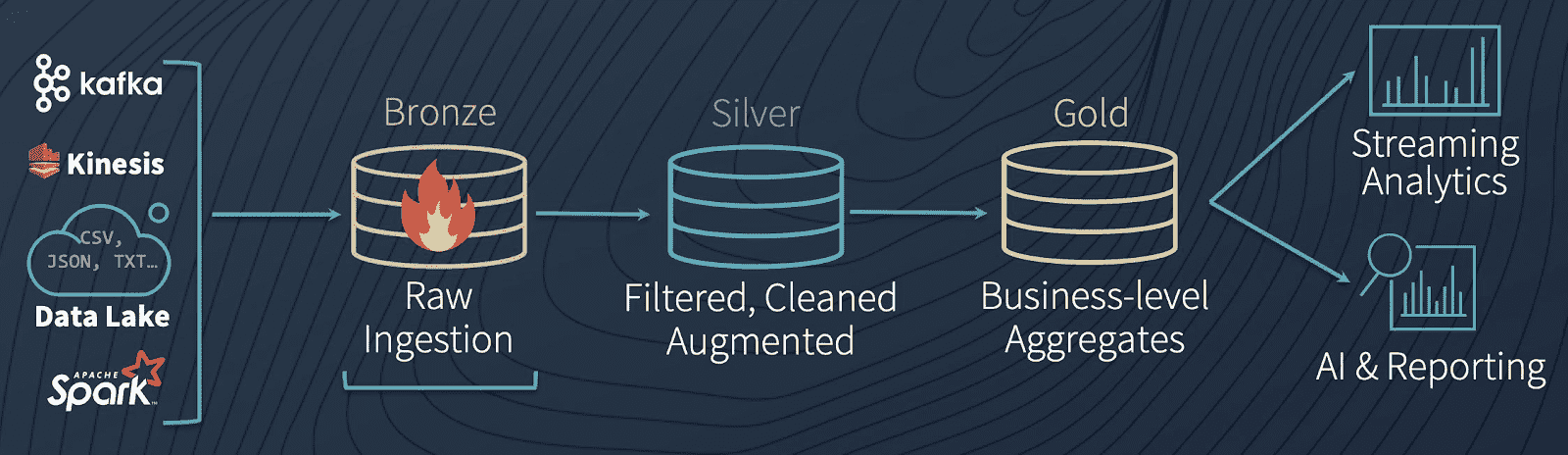
Vào foler assets, ta sẽ tạo các assets là các bảng được load từ MySQL, hãy tạo một file bronze_layer.py ư sau:
from dagster import asset, Output, AssetIn, AssetOut
import pandas as pd
tables = [
"leagues",
"players",
"games",
"appearances",
"teamstats",
"teams"
]
def asset_factory (table: str):
@asset(
name=table,
io_manager_key="minio_io_manager",
required_resource_keys={"mysql_io_manager"},
key_prefix=["football", "bronze"],
compute_kind="SQL",
group_name="bronze_layer"
)
def _asset(context) -> Output[pd.DataFrame]:
sql_stm = f"SELECT * FROM {table}"
pd_data = context.resources.mysql_io_manager.extract_data(sql_stm)
context.log
return Output(
pd_data,
metadata={
"table": table,
"records": len(pd_data)
}
)
return _assetasset factory. Nghĩa là thay vì tạo 6 assets giống nhau bằng cách viết 6 function cho từng asset, mình sẽ làm 1 template chung rồi lần lượt loop tên các bảng thôi :)) Việc loop đó sẽ thực hiện trong __init__.pyLúc này các bảng đã được load vào MinIO, các bước sau chỉ cần lấy từ MinIO ra và xử lý tiếp thôi
Transformation
Tiếp tục tạo file silver_layer.py cùng folder với bronze layer:
from dagster import asset, Output, AssetIn
import pandas as pd
@asset(
io_manager_key="minio_io_manager",
required_resource_keys={"minio_io_manager"},
ins={
"teamstats": AssetIn(
key_prefix=["football", "bronze"]
),
"games": AssetIn(
key_prefix=["football", "bronze"]
),
"leagues": AssetIn(
key_prefix=["football", "bronze"]
)
},
key_prefix=["football", "silver"],
description='Statistic of teams in games',
group_name="Silver_layer",
compute_kind="Pandas"
)
def silver_statsTeamOnGames(teamstats: pd.DataFrame, games: pd.DataFrame, leagues: pd.DataFrame) -> Output[pd.DataFrame]:
ts = teamstats.copy()
gs = games.copy()
lgs = leagues.copy()
#Drop unsusable columns in games
gs.drop(columns=gs.columns.to_list()[13:], inplace=True)
#create StatperLeagueSeason
result = pd.merge(ts, gs, on="gameID")
result = result.merge(lgs, on="leagueID", how="left")
result.drop(columns=['season_y', 'date_y'],inplace=True)
result = result.rename(columns={'season_x': 'season', 'date_x': 'date'})
return Output(
result,
metadata={
"table": "statsTeamOnGames",
"records": len(result)
}
)
@asset(
io_manager_key="minio_io_manager",
required_resource_keys={"minio_io_manager"},
ins={
"appearances": AssetIn(
key_prefix=["football", "bronze"]
),
"games": AssetIn(
key_prefix=["football", "bronze"]
),
"players": AssetIn(
key_prefix=["football", "bronze"]
)
},
key_prefix=["football", "silver"],
group_name="Silver_layer",
description='statistic of players in games',
compute_kind="Pandas"
)
def silver_playerAppearances(appearances: pd.DataFrame, games: pd.DataFrame, players: pd.DataFrame) -> Output[pd.DataFrame]:
app = appearances.copy()
ga = games.copy()
pla = players.copy()
#Drop unusable column
ga.drop(columns=ga.columns.to_list()[13:], inplace=True)
#Merge
player_appearances = pd.merge(app, pla, on="playerID", how="left")
player_appearances = pd.merge(player_appearances, ga, on="gameID", how="left")
#drop unecessary columns and rename
player_appearances.drop(columns=['leagueID_y'],inplace=True)
player_appearances.rename(columns={'leagueID_x': 'leagueID'}, inplace=True)
return Output(
player_appearances,
metadata={
"table": "playerAppearances",
"records": len(player_appearances)
}
)
@asset(
io_manager_key="minio_io_manager",
required_resource_keys={"minio_io_manager"},
ins={
"teams": AssetIn(
key_prefix=["football", "bronze"]
)
},
key_prefix=["football", "silver"],
group_name="Silver_layer",
description='Teams',
compute_kind="Pandas"
)
def silver_teams(teams: pd.DataFrame) -> Output[pd.DataFrame]:
return Output(
teams,
metadata={
"table": 'teams',
'records': len(teams)
}
)Lúc này mình có 3 silver assets, được join từ các bảng ở bronze
Tiếp đến là gold_layer, lúc này ta sẽ tính các thông số thống kê của từng giải đâu từng mùa, các thống kê của cầu thủ trong 90 phút thi đấu, và cả thống kê của từng cầu thủ trong từng mùa giải
gold_layer.py sẽ có nội dung:
from dagster import asset, Output, AssetIn
import pandas as pd
@asset(
io_manager_key="minio_io_manager",
ins={
"silver_statsTeamOnGames": AssetIn(
key_prefix=["football", "silver"]
)
},
group_name="Gold_layer",
key_prefix=["football", "gold"],
description='Statistic of all league in each season',
compute_kind="Pandas"
)
def gold_statsPerLeagueSeason(silver_statsTeamOnGames: pd.DataFrame) -> Output[pd.DataFrame]:
st = silver_statsTeamOnGames.copy()
result = (
st.groupby(['name', 'season'])
.agg({"goals": "sum", "xGoals": "sum", "shots": "sum", "shotsOnTarget": "sum", "fouls": "sum", "yellowCards": "sum", "redCards": "sum",'corners': 'sum', "gameID": 'count'})
.reset_index()
)
result = result.rename(columns={'gameID':"games"})
result['goalPerGame']= result.goals/result.games
result['season'] = result['season'].astype('string')
return Output(
result,
metadata={
'table': 'statPerLeagueSeason',
'records': len(result)
}
)
@asset(
io_manager_key="minio_io_manager",
ins={
"silver_playerAppearances": AssetIn(
key_prefix=["football", "silver"]
)
},
group_name="Gold_layer",
key_prefix=["football", "gold"],
description='Statistic of all player in each season',
compute_kind="Pandas"
)
def gold_statsPerPlayerSeason(silver_playerAppearances: pd.DataFrame) -> Output[pd.DataFrame]:
st = silver_playerAppearances.copy()
statsPerPlayerSeason = (
st.groupby(['playerID','name','season'])
.agg({'goals': 'sum','shots': 'sum','xGoals':'sum','xGoalsChain':'sum','xGoalsBuildup':'sum','assists':'sum','keyPasses':'sum','xAssists':'sum','time': 'sum'})
.reset_index()
)
statsPerPlayerSeason['gDiff'] = statsPerPlayerSeason['goals'] - statsPerPlayerSeason['xGoals']
statsPerPlayerSeason['gDiffRatio'] = statsPerPlayerSeason['goals'] / statsPerPlayerSeason['xGoals']
statsPerPlayerSeason['gDiffRatio'] = statsPerPlayerSeason['gDiffRatio'].fillna(0)
return Output(
statsPerPlayerSeason,
metadata={
'table': 'statsPerPlayerSeason',
'records': len(statsPerPlayerSeason)
}
)
@asset(
io_manager_key="minio_io_manager",
ins={
"gold_statsPerPlayerSeason": AssetIn(
key_prefix=["football", "gold"]
)
},
group_name="Gold_layer",
key_prefix=["football", "gold"],
description='Statistic of all player in 90 min',
compute_kind="Pandas"
)
def gold_statsPlayerPer90(gold_statsPerPlayerSeason: pd.DataFrame) -> Output[pd.DataFrame]:
statsPerPLayerSeason = gold_statsPerPlayerSeason.copy()
statsPlayerPer90 = statsPerPLayerSeason[statsPerPLayerSeason['season'].isin(['2018','2019','2020'])]
statsPlayerPer90 = (
statsPlayerPer90.groupby(['playerID', 'name'])
.agg(total_goals=('goals','sum'),total_assists=('assists','sum'),total_time=('time','sum'))
.reset_index()
)
statsPlayerPer90['goalsPer90'] = statsPlayerPer90['total_goals'] / statsPlayerPer90['total_time'] * 90
statsPlayerPer90['assistsPer90'] = statsPlayerPer90['total_assists'] / statsPlayerPer90['total_time'] * 90
statsPlayerPer90['scorers'] = statsPlayerPer90['total_goals'] + statsPlayerPer90['total_assists']
statsPlayerPer90 = statsPlayerPer90[statsPlayerPer90['scorers'] > 30]
return Output(
statsPlayerPer90,
metadata={
'table': 'statsPerPlayerSeason',
'records': len(statsPlayerPer90)
}
)Cuối cùng sau khi đã tạo ra data có giá trị phân tích và sạch sẽ, ta sẽ load vào data warehouse (Postgres)
Load
Trước hết hãy tạo IO Manager cho Postgres để quản lý việc load cleaned data. Ta tạo file psql_io_manager.py ở vị trí mà ta đã tạo 2 io manager trước với nội dung:
from contextlib import contextmanager
from datetime import datetime
import pandas as pd
from dagster import IOManager, OutputContext, InputContext
from sqlalchemy import create_engine
@contextmanager
def connect_psql(config):
conn_info = (
f"postgresql+psycopg2://{config['user']}:{config['password']}" + f"@{config['host']}:{config['port']}" + f"/{config['database']}"
)
db_conn = create_engine(conn_info)
try:
yield db_conn
except Exception:
raise
class PostgreSQLIOManager(IOManager):
def __init__(self, config):
self._config = config
def load_input(self, context: InputContext) -> pd.DataFrame:
pass
def handle_output(self, context: OutputContext, obj: pd.DataFrame):
schema, table = context.asset_key.path[-2], context.asset_key.path[-1]
with connect_psql(self._config) as conn:
# insert new data
ls_columns = (context.metadata or {}).get("columns", [])
obj[ls_columns].to_sql(
name=f"{table}",
con=conn,
schema=schema,
if_exists="replace",
index=False,
chunksize=10000,
method="multi"
)Sau đó, tạo một asset warehouse_layer.py:
from dagster import multi_asset, Output, AssetIn, AssetOut, asset
import pandas as pd
@multi_asset(
ins={
"gold_statsPerLeagueSeason": AssetIn(
key_prefix=["football", "gold"]
)
},
outs={
"statsperleagueseason": AssetOut(
io_manager_key="psql_io_manager",
key_prefix=["statsPerLeagueSeason", 'analysis'],
metadata={
"columns": [
"name",
"season",
"goals",
"xGoals",
"shots",
"shotsOnTarget",
"fouls",
"yellowCards",
"redCards",
"corners",
"games",
"goalPerGame"
]
}
),
},
compute_kind="PostgreSQL",
group_name="Warehouse_layer"
)
def statsPerLeagueSeason(gold_statsPerLeagueSeason: pd.DataFrame) -> Output[pd.DataFrame]:
return Output(
gold_statsPerLeagueSeason,
metadata={
"schema": "analysis",
"table": "statsPerLeagueSeason",
"records": len(gold_statsPerLeagueSeason)
}
)
@multi_asset(
ins={
"gold_statsPerPlayerSeason": AssetIn(
key_prefix=['football', 'gold']
)
},
outs={
"statsperplayerseason": AssetOut(
io_manager_key="psql_io_manager",
key_prefix=["statsPerPlayerSeason", 'analysis'],
metadata={
"columns": [
"playerID",
"name",
"season",
"goals",
"shots",
"xGoals",
"xGoalsChain",
"xGoalsBuildup",
"assists",
"keyPasses",
"xAssists",
"gDiff",
"gDiffRatio"
]
}
)
},
compute_kind="PostgreSQL",
group_name="Warehouse_layer"
)
def statsPerPlayerSeason(gold_statsPerPlayerSeason: pd.DataFrame) -> Output[pd.DataFrame]:
return Output(
gold_statsPerPlayerSeason,
metadata={
"schema": "analysis",
"table": "statsPerPlayerSeason",
"records": len(gold_statsPerPlayerSeason)
}
)
@multi_asset(
ins={
"gold_statsPlayerPer90": AssetIn(
key_prefix=['football', 'gold']
)
},
outs={
"statsplayerper90": AssetOut(
io_manager_key="psql_io_manager",
key_prefix=["statsPlayerPer90", 'analysis'],
metadata={
"columns": [
'playerID',
'name',
'total_goals',
'total_assists',
'total_time',
'goalsPer90',
'assistsPer90',
'scorers'
]
}
)
},
compute_kind="PostgreSQL",
group_name="Warehouse_layer"
)
def statsPlayerPer90(gold_statsPlayerPer90: pd.DataFrame) -> Output[pd.DataFrame]:
return Output(
gold_statsPlayerPer90,
metadata={
"schema": "analysis",
"table": "statsPlayerPer90",
"records": len(gold_statsPlayerPer90)
}
)Run system
Cuối cùng, ta sẽ kết hợp tất cả các asset lại giúp dagster nhận diện và quản lý với file __init__.py ở etl_pipeline/etl_pipeline/__init__.py
import os
from dagster import Definitions
from .assets.silver_layer import *
from .assets.gold_layer import *
from .assets.bronze_layer import *
from .assets.warehouse_layer import *
from .resources.minio_io_manager import MinIOIOManager
from .resources.mysql_io_manager import MySQLIOManager
from .resources.psql_io_manager import PostgreSQLIOManager
MYSQL_CONFIG = {
"host": os.getenv("MYSQL_HOST"),
"port": os.getenv("MYSQL_PORT"),
"database": os.getenv("MYSQL_DATABASE"),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD")
}
MINIO_CONFIG = {
"endpoint_url": os.getenv("MINIO_ENDPOINT"),
"bucket": os.getenv("DATALAKE_BUCKET"),
"aws_access_key_id": os.getenv("AWS_ACCESS_KEY_ID"),
"aws_secret_access_key": os.getenv("AWS_SECRET_ACCESS_KEY")
}
PSQL_CONFIG = {
"host": os.getenv("POSTGRES_HOST"),
"port": os.getenv("POSTGRES_PORT"),
"database": os.getenv("POSTGRES_DB"),
"user": os.getenv("POSTGRES_USER"),
"password": os.getenv("POSTGRES_PASSWORD")
}
ls_asset=[asset_factory(table) for table in tables] + [silver_statsTeamOnGames,
silver_teams ,
silver_playerAppearances,
gold_statsPerLeagueSeason,
gold_statsPerPlayerSeason,
gold_statsPlayerPer90,
statsPerLeagueSeason,
statsPerPlayerSeason,
statsPlayerPer90]
defs = Definitions(
assets=ls_asset,
resources={
"mysql_io_manager": MySQLIOManager(MYSQL_CONFIG),
"minio_io_manager": MinIOIOManager(MINIO_CONFIG),
"psql_io_manager": PostgreSQLIOManager(PSQL_CONFIG),
}
)sau đó hãy dùng lệnh sau để cập nhật các assets
docker restart etl_pipelineCheck UI
Hãy kiểm tra Dagit UI ở localhost:3001 để chắc chắn rằng mọi thứ vẫn ổn

Ngoài ra cũng có thể check MinIO: localhost:9000
Visualization
Cuối cùng là vẽ dashboard, đầu tiên ta cần phải lấy được data từ psql, hãy vào tạo file: ./streamlit/src/psql_connect.py:
import os
import psycopg2
from dotenv import load_dotenv
import pandas as pd
#load environment
load_dotenv()
#list table in database
table = ['statsperleagueseason','statsperplayerseason', 'statsplayerper90']
PSQL_CONFIG = {
"host": os.getenv("POSTGRES_HOST"),
"port": os.getenv("POSTGRES_PORT"),
"database": os.getenv("POSTGRES_DB"),
"user": os.getenv("POSTGRES_USER"),
"password": os.getenv("POSTGRES_PASSWORD")
}
#create connection
def init_connection(config):
return psycopg2.connect(
database=config['database'],
user=config['user'],
password=config['password'],
host=config['host'],
port=config['port']
)
def extract_data():
conn = init_connection(PSQL_CONFIG)
return [pd.read_sql(f'SELECT * FROM analysis.{tab}', conn) for tab in table]Cuối cùng là tạo main.py ngay trong thư mục scr:
import streamlit as st
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from psql_connect import extract_data
import numpy as np
# #extract data from PostgreSQL
ls_df = extract_data()
l_season = ls_df[0]
p_season = ls_df[1]
p_match = ls_df[2]
st.set_page_config(page_title = 'Dashboard Football',
layout='wide',
page_icon='chart_with_upwards_trend')
#Overview
def overview(table: pd.DataFrame, detail: str):
if (st.checkbox('Do you want to see Data ?')):
table
col1, col2 = st.columns(2)
co_df = table.columns.to_list()
with col1:
st.bar_chart(table.describe())
if (st.checkbox('Do you want to see describe each column ?')):
for col in co_df:
if table[col].dtypes not in ['int64', 'float64']:
continue
st.bar_chart(table[col].describe())
with col2:
st.caption(f':red[Columns]: {len(co_df)}')
st.caption(f':red[Records]: {len(table)}')
st.caption(f':red[Description]: {detail}')
st.caption(f':red[Columns name]:{co_df}')
#league statistic
def statleague():
Cards = l_season[['name','season','yellowCards', 'redCards', 'fouls']]
#Card_fouls
col1, col2 = st.columns(2)
with col1:
#Goals per games
fig = px.bar(l_season, x="name", y="goalPerGame", color="name", barmode="stack",
facet_col="season",
labels={"name": "League", "goals/games": "GPG"})
fig.update_layout(showlegend=False,
title='Goals per Game')
st.plotly_chart(fig)
#fouls
fig = px.line(Cards, x='season', y='fouls', color='name')
fig.update_layout(title='Fouls of leagues',
xaxis_title='Season',
yaxis_title='Fouls',
legend_title='League')
st.plotly_chart(fig)
with col2:
#Red card
fig = px.line(Cards, x='season', y='redCards', color='name')
fig.update_layout(title='Red Cards of leagues',
xaxis_title='Season',
yaxis_title='RedCards',
legend_title='League')
st.plotly_chart(fig)
#yellow card
fig = px.line(Cards, x='season', y='yellowCards', color='name')
fig.update_layout(title='Yellow Cards of leagues',
xaxis_title='Season',
yaxis_title='YellowCards',
legend_title='League')
st.plotly_chart(fig)
#Player statistic
def statplayer():
col1, col2 = st.columns(2)
with col1:
#Best offensive player
top_player90= p_match[(p_match['goalsPer90'] > 0.8) | (p_match['assistsPer90'] > 0.4)]
fig = px.scatter(p_match[['name','goalsPer90', 'assistsPer90']], x='goalsPer90', y='assistsPer90', hover_name='name')
fig.add_trace(
go.Scatter(x=top_player90['goalsPer90'], y=top_player90['assistsPer90'],
mode='markers+text', marker_size=5, text=top_player90['name'],
textposition='bottom center', textfont=dict(size=15))
)
fig.update_layout(title='Best offensive Players (2018-2020)', xaxis_title='Goals Per 90min', yaxis_title='Assists Per 90min')
st.plotly_chart(fig)
#goals-xgoal
fig = px.scatter(p_season, x="xGoals", y="goals", color=(p_season['xGoals'] - p_season['goals'] < 10),
color_discrete_sequence=["red", "green"], opacity=0.5)
fig.update_layout(title="Goals (G) and Expected Goals (xG)",
xaxis_title="xG",
yaxis_title="G",
)
st.plotly_chart(fig)
with col2:
#Top score player
topPlayer = p_season.groupby(['name']).agg({'goals': 'sum'}).sort_values('goals', ascending=False).reset_index()
topPlayer = p_season[p_season['name'].isin(topPlayer.name[:5])]
fig = px.line(topPlayer, x='season',y='goals',color='name')
fig.update_layout(
title='Top score player (season 2014 - 2020)',
xaxis_title='Season',
yaxis_title='Goals',
legend_title='PLayers'
)
st.plotly_chart(fig)
# Page status
st.sidebar.markdown("# Main page :pushpin:")
introduction = '''
Đây là trang thông tin tổng quan về phân tích dữ \
liệu của **dataset Football**.
Dữ liệu được load từ database __PostgreSQL__ (localhost:5432) để làm phân tích.
'''
st.sidebar.write(introduction)
st.markdown('# Football Analysis :soccer:')
'''
Tổng hợp phân tích data được transform từ 5 giải vô dịch quốc gia hàng đầu châu Âu từ mùa 2014 - 2020 \
từ bộ dataset **Football**
'''
with st.container():
st.markdown("<hr/>", unsafe_allow_html=True)
## Data overview
st.markdown("## Data Overview :bar_chart:")
first_col, second_col = st.columns(2)
with first_col:
st.markdown("### **Tables**")
num=len(ls_df)
st.markdown(f"<h2 style='text-align: left; color: red;'>{num}</h2>", unsafe_allow_html=True)
with second_col:
st.markdown("### **DataBase**")
st.markdown(f"##### **PostgreSQL**")
if st.checkbox('Click to overview detail tables'):
option = st.selectbox(
'Choose table you want to see ?',
['statsPerLeagueSeason', 'statsPerPlayerSeason', 'statsPlayerPer90'])
if option == 'statsPerLeagueSeason':
detail = '''
Đây là bảng mô tả thống kê của các giải đấu từ mùa 2014 - 2020
'''
overview(l_season, detail)
elif option == 'statsPerPlayerSeason':
detail='''
Bảng dữ liệu thống kê các chỉ số của một cầu thủ đạt được trong từng mùa giải ở cả 5 giải đấu
'''
overview(p_season, detail)
else:
detail='''
Bảng dữ liệu thống kê chỉ số của một cầu thủ trong 90 phút ở tất cả các mùa giải ở tất cả giải đấu
'''
overview(p_match,detail)
### Statistic
with st.container():
st.markdown("<hr/>", unsafe_allow_html=True)
st.markdown("## Football Statistic :bar_chart:")
option = st.selectbox(
'**Choose statistic**',
['Leagues', 'Players']
)
if option == 'Leagues':
statleague()
else:
statplayer()Đã xong rồi, hãy check localhost:8501 để xem thành quả nhé :))))
Conclusion
Cuối cùng cũng đã xong một project xây dựng data pipeline cơ bản, trong lúc thực hiện chắc chắn sẽ có cả tấn lỗi xảy ra, nhưng OG tin là mọi gian khó đều sẽ vượt quan được, thứ đọng lại chính là kiến thức và kỹ năng của chúng ta. Chúc bạn thành công và đón xem tiếp các dự án tiếp theo của OG nhé !
-Mew-
Related Content
Football ETL Analysis
A Data Engineer project building pipeline to analyze football data
Read more...