Spotify Analysis

Source
Youtube Link:
.svg_16893588212685776551.png)
Spotify Analysis with PySpark
Hello ! Hello ! Lại là OG đây. Lần này mình sẽ cùng nhau xây dựng End-to-End ELT data pipeline và một Recommender System dựa trên dữ liệu phân tích từ Spotify API nhé. Không dài dòng nữa, bắt đầu thôi nào.
Introduction
Project lần này là xây dựng hệ thống phân tích nhạc từ Spotify như diagram sau
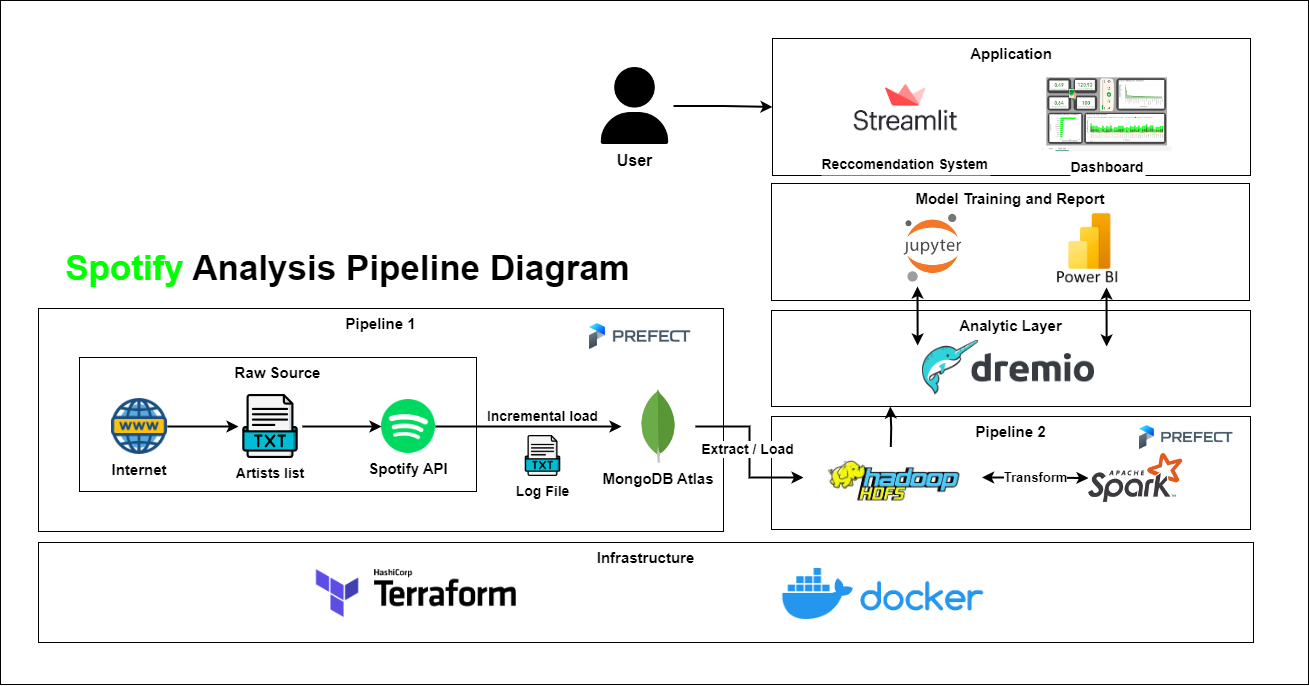
Trong diagram bao gồm những thành phần sau:
- Infrastructure: Ta sẽ sử dụng Docker để set up cho hầu hết các frameworks sử dụng trong hệ thống và Terraform (Optional) để set up cho MongoDB.
- Pipeline 1: Đây là pipeline sẽ thực hiện incremental load vào MongoDB mỗi kéo data từ Spotify API về.
- Pipeline 2: Data Pipeline này thực hiện việc chính là ELT (Extract, Load, Transform) để xử lý và chuẩn hóa dữ liệu JSON từ MongoDB. Việc xử lý cấu trúc dữ liệu phức tạp và lồng nhau của JSON chủ yếu sẽ được thực hiện bằng pySpark (Python API của Apache Spark) ngay trên HDFS (Hadoop Distributed File System)
- Analytic Layer: Để có thể sử dụng phân tích được, ta sẽ apply một lớp phân tích lên trên Hadoop. Ở project này ta sẽ sử dụng Dremio để cho việc đó.
- Machine learning and Dashboard: Ở phần này chủ yếu là việc training mô hình machine learning model cho hệ thống gợi ý âm nhạc spoitfy. Ngoài ra cũng có thể PowerBI để tạo các Dashboard để phân tích từ dữ liệu ở Dremio.
- Application: Cuối cùng ta sẽ dùng Streamlit để viết một web đơn giản để làm hệ thống gợi ý và tìm kiếm nhạc. Ngoài ra người dùng cũng có thể tương tác với BI Dashboard ở layer này
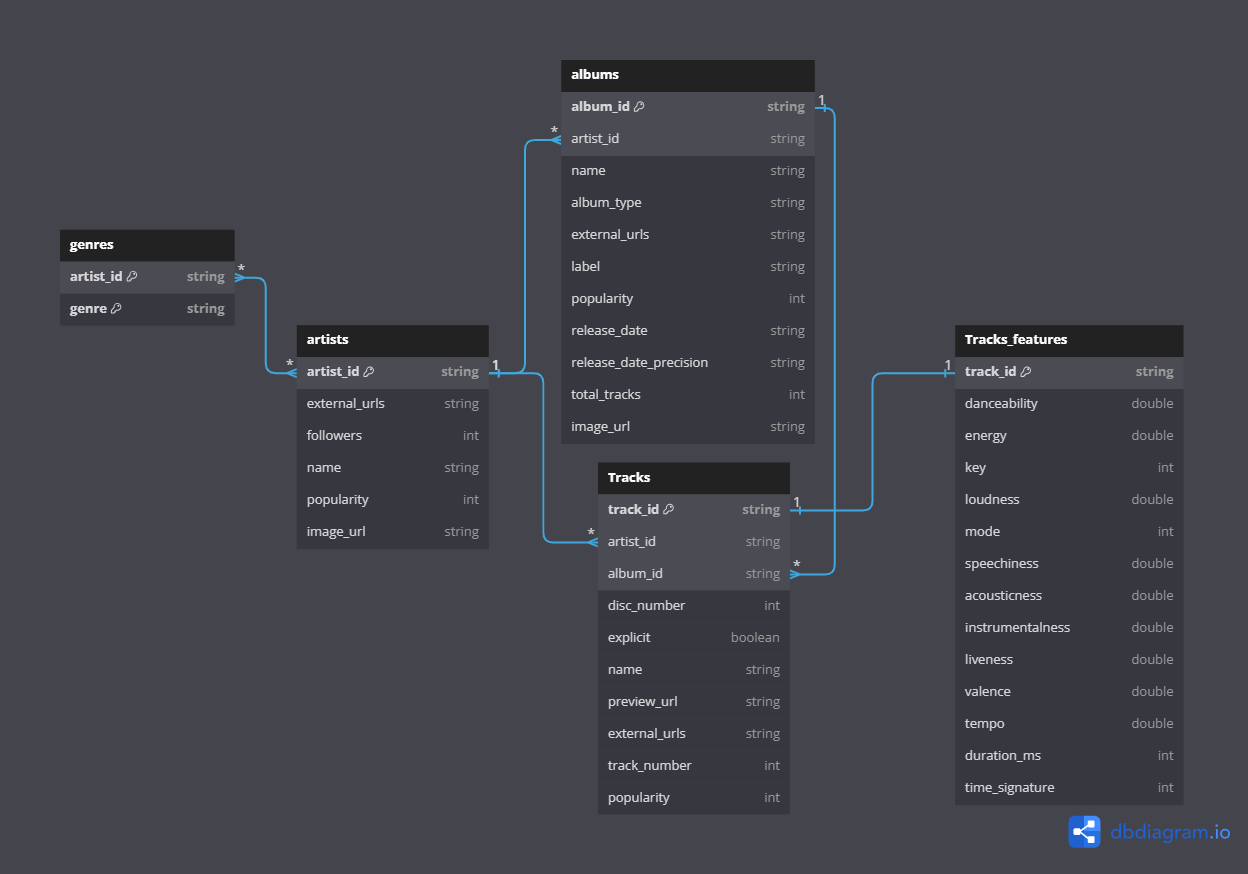
Data Schema
Nguồn data của chúng ta đến từ Spotify API. Ngoài ra ta cũng sẽ cào thêm một danh sách nghệ sĩ trên Spotify từ trang Sportify Artists. Data sau khi đã được xử lý cuối cùng sẽ có schema như sau:
Infrastructure
Ta sẽ sử dụng chủ yếu là Docker để cấu hình cho hầu hết các framework trong hệ thống thông qua docker-compose.yml file. Chỉ riêng có MongoDB Atlas thì có thể set up bằng nhiều cách khác nhau.
Apache Hadoop
Đầu tiên ta sẽ set up Apache Hadoop bằng Docker Compose. Như đã biết Hadoop là một framework được viết bằng Java được giới thiệu bởi Google vào năm 2006 và ứng dụng công nghệ hệ thống phân tán để lưu trữ và xử lý Big Data. Hadoop được xây dựng đựa trên ba thành phần chính:
- HDFS (Hadoop Distributed File System): là hệ thống file phân tán được sử dụng để lưu trữ dữ liệu
- YARN (Yet Another Resouce Negotiator): là một framework quản lý và phân bổ tài nguyên để vận hành các ứng dụng trên Hadoop
- MapReduce: là một framework lập trình xử lý và tính toán dữ liệu song song trong môi trường hệ thống phân tán.

HDFS và YARN trong Hadoop
Trong project này, ta sẽ lượt bớt phần setup MapReduce trong Hadoop Cluster và thay vào đó chỉ là HDFS và YARN thôi (vì phần xử lý tính toán ta sẽ thay thế bằng Apache Spark). Ngoài ra vì là project PoC (Proof of Concept), ta sẽ đơn giản hóa Hadoop cluster với 1 Master Node, 1 Worker Node mà thôi.
volumes:
hadoop_datanode:
hadoop_namenode:
services:
namenode:
container_name: namenode
image: apache/hadoop:3
hostname: namenode
command: bash -c "if [ ! -f /tmp/hadoop-root/dfs/name/.formatted ]; then hdfs namenode -format && touch /tmp/hadoop-root/dfs/name/.formatted; fi && hdfs namenode"
ports:
- 9870:9870
- 8020:8020
- 9000:9000
user: root
env_file:
- .env
volumes:
- hadoop_namenode:/tmp/hadoop-root/dfs/name
networks:
- docker-net
datanode:
image: apache/hadoop:3
container_name: datanode
hostname: datanode
command: ["hdfs", "datanode"]
ports:
- 9864:9864
- 9866:9866
expose:
- 50010
env_file:
- .env
user: root
volumes:
- hadoop_datanode:/tmp/hadoop-root/dfs/data
networks:
- docker-net
resourcemanager:
image: apache/hadoop:3
hostname: resourcemanager
command: ["yarn", "resourcemanager"]
ports:
- 8088:8088
env_file:
- .env
volumes:
- ./test.sh:/opt/test.sh
networks:
- docker-net
nodemanager:
image: apache/hadoop:3
command: ["yarn", "nodemanager"]
env_file:
- .env
ports:
- 8188:8188
networks:
- docker-netTa sẽ chủ yếu sử dụng HDFS để làm Datalake cho project này. Ngoài ra có thể truy cập vào các services của Hadoop thông qua:
- Namenode:
localhost:9870 - Datanode:
localhost:9864 - Resouces Manager (YARN):
localhost:8088
Prefect
Prefect là một orchestration tool khá dễ dùng và dễ bắt đầu. Với giao diện bắt mắt và tính dễ tiếp cận, framework này giúp cho việc lên lịch, sắp xếp và chạy các task hay thậm chí là chạy song song (concurrent task). Ta sẽ set up một prefect server và prefect API bằng docker như sau:
prefect-server:
build:
context: ./prefect
image: prefect
hostname: prefect-server
container_name: prefect-server
volumes:
- prefect:/root/.prefect
command: prefect server start
environment:
- PREFECT_UI_URL=http://127.0.0.1:4200/api
- PREFECT_API_URL=http://127.0.0.1:4200/api
- PREFECT_SERVER_API_HOST=0.0.0.0
ports:
- 4200:4200
networks:
- docker-net
prefect:
image: prefect:latest
container_name: prefect
restart: always
volumes:
- "./prefect/flows:/opt/prefect/flows"
- "/etc/timezone:/etc/timezone:ro"
- "/etc/localtime:/etc/localtime:ro"
env_file:
- .env
networks:
- docker-net
depends_on:
- prefect-server
Và trong lúc setup, ta sẽ không sử dụng built-in image PrefectHQ mà thay vào đó sẽ tự build một custom image để có thể dễ tùy biến. Ngoài các module cho python
trong requirements.txt ta sẽ cần phải config thêm Java 11 để tương thích với pyspark
ARG IMAGE_VARIANT=slim-buster
ARG OPENJDK_VERSION=11
ARG PYTHON_VERSION=3.11.0
FROM python:${PYTHON_VERSION}-${IMAGE_VARIANT} AS py3
FROM openjdk:${OPENJDK_VERSION}-${IMAGE_VARIANT}
COPY --from=py3 / /
WORKDIR /opt/prefect
COPY requirements.txt .
RUN pip install -r requirements.txt --trusted-host pypi.python.org --no-cache-dir
COPY flows /opt/prefect/flows
# Run our flow script when the container starts
CMD ["python", "flows/main_flow.py"]Ta có thể truy cập UI Prefect thông qua
localhost:4042để trigger pipeline.
Dremio
Bây giờ ta đã có một datalake là hadoop HDFS, tuy nhiên Object Storange như HDFS không cung cấp khả năng phân tích hay truy vấn, do đó ta sẽ cần xây dựng một Analytic Layer trên HDFS. Ở vị trí này có khá nhiều lựa chọn như Trino, Hive,… Tuy nhiên ở project này ta sẽ dùng một Lakehouse platform là Dremio.
Dremio là một mã nguồn mở data-as-a-service hỗ trợ phân tích và dễ dàng kết nối với đa dạng nguồn data khác nhau và tất nhiên trong đó có Hadoop. Dremio cung cấp khả truy vấn mạnh mẽ với SQL engine và một giao diện thân thiện
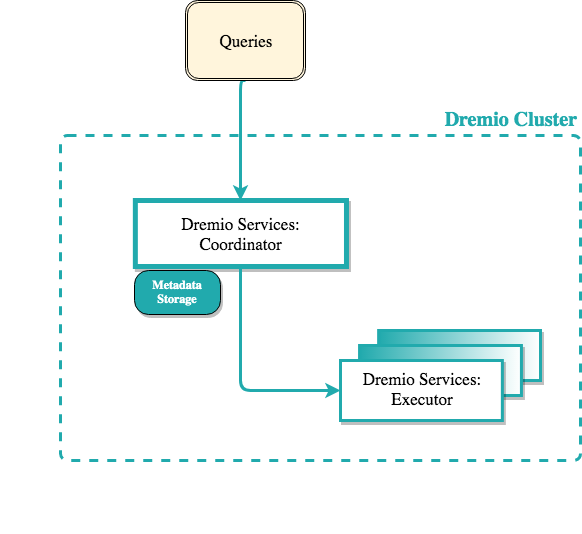
Dremio Cluster
Ta sẽ config một dremio cluster với dremio-oss image. Image này bao gồm:
- Embedded Zookeeper
- Master Coordinator
- Execuor
dremio:
image: dremio/dremio-oss
hostname: dremio
container_name: dremio
restart: always
user: root
volumes:
- dremio_data:/var/lib/dremio
- dremio_data:/localFiles
- dremio_data:/opt/dremio
ports:
- "9047:9047" # Web UI (HTTP)
- "31010:31010" # ODBC/JDBC client
- "32010:32010" # Apache Arrow Flight clients
networks:
- docker-netSau khi deploy thành công, ta có thể đăng nhập vào dremio ở
localhost:9047với username=dremio và password=dremio123
MongoDB with Terraform
Về Terraform: HashiCorp Terraform là một công cụ “insfrastructure as code” giúp ta setup và config những tài nguyên cả on-prem hay cloud chỉ với việc viết configuration file.
MongoDB Atlas: có thể không cần config trong docker compose và hoàn toàn có thể set up thủ công ở Đây. Tuy nhiên trong phần này thì ta sẽ làm điều đó tự động bằng Terraform.
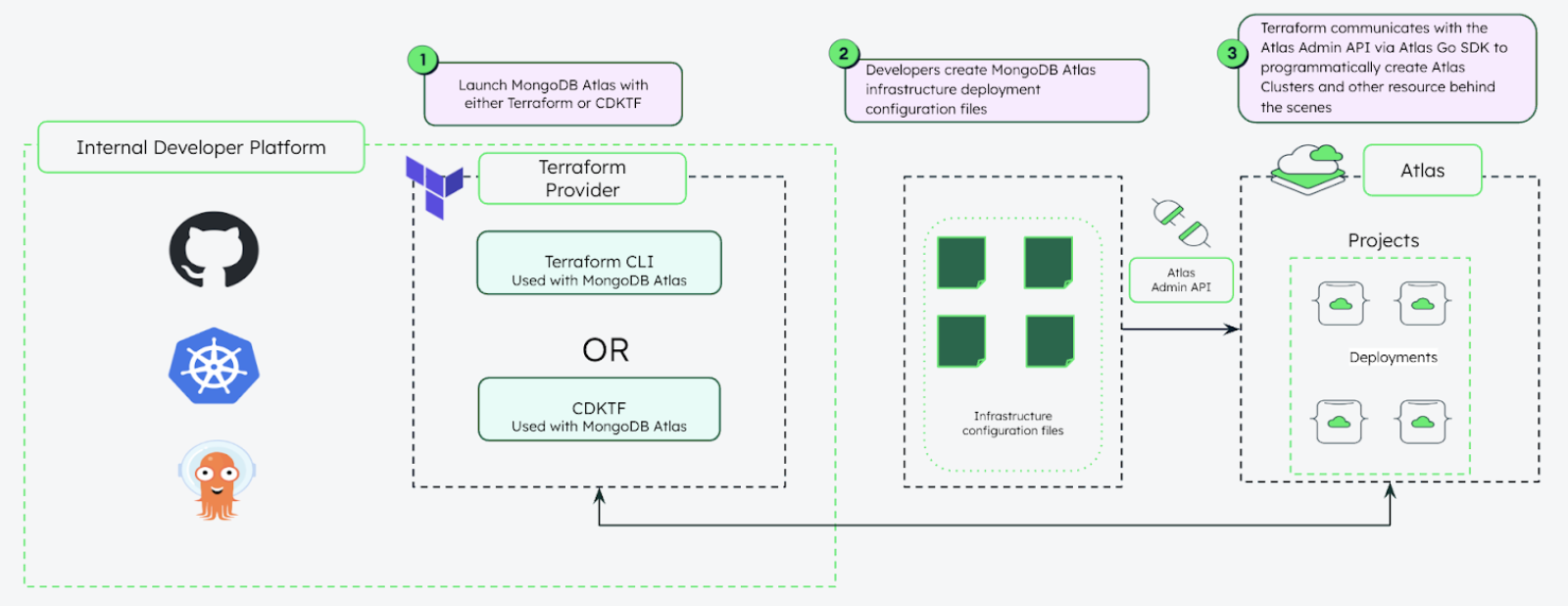
Đầu tiên ta càn phải có tài khoản MongoDB Atlas, sau đó bước đầu tiên là sẽ set up vài variables trong file variable.tf. File này sẽ lưu đa số các biến môi trường, API key, token,….
variable.tf có thể đọc ở ĐâyVới terraform, ta sẽ chủ yếu chạy file main.tf vì file này sẽ lưu mọi config về cluster muốn deploy.
Ta sẽ sử dụng MongoDB Atlas Provider và gọi lại các variables (được set trong file file variable.tf trước đó)
terraform {
required_providers {
mongodbatlas = {
source = "mongodb/mongodbatlas",
version = "1.8.0"
}
}
}
provider "mongodbatlas" {
public_key = var.public_key
private_key = var.private_ke
}mongdodbatlas_project: Config project khỏi tạo
resource "mongodbatlas_project" "spotify_project" {
name = "spotify_project"
org_id = var.org_id
is_collect_database_specifics_statistics_enabled = true
is_data_explorer_enabled = true
is_performance_advisor_enabled = true
is_realtime_performance_panel_enabled = true
is_schema_advisor_enabled = true
}mongodbatlas_cluster: setup cluster cho atlas, ta sẽ host trên gcp (có thể chọn azure hay aws đều được)
resource "mongodbatlas_cluster" "spotify" {
name = var.cluster_name
project_id = mongodbatlas_project.spotify_project.id
backing_provider_name = "GCP"
provider_name = "TENANT"
provider_instance_size_name = var.cluster_size
provider_region_name = var.region
}Chạy lệnh deploy cluster
Sau khi đã chuẩn bị hoàn tất các configuration, việc còn lại là chạy các lệnh tf cli để set up plan
terraform init # set up provider for atlas
terraform planSau đó, nhập yes để tiếp tục quá trình set up. cuối dùng để deploy cluster thì ta sẽ chỉ cần nhập terraform apply. sau đó ta sẽ nhận được kết quả giống thế này
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.
Outputs:
password = "123"
srv_address = "mongodb+srv://spotify-cluster.kdglyul.mongodb.net"
user = "root"Hãy chú ý các thông tin ở ba dòng cuối là password, srv_address và user. ta sẽ cần những thông tin này cho file .env để set up connection với Atlas sau này. Đó sẽ là các biến MONGODB_PASS, MONGODB_SRV và MONGODB_USER
terraform destroy. hãy cẩn thận vì lệnh này có thể xóa hết cluster và cả dataPipeline 1
Data pipeline này thực hiện việc chính là pooling api để crawl data từ spotify api và incremental load data vào mongodb atlas. để giải quyết vấn đề
về rate limit, ta sẽ config cho flow này được tự động trigger mỗi 2 phút 5 giây để crawl một batch gồm lần lượt thông tin 5 artists từ file danh sách artists.txt
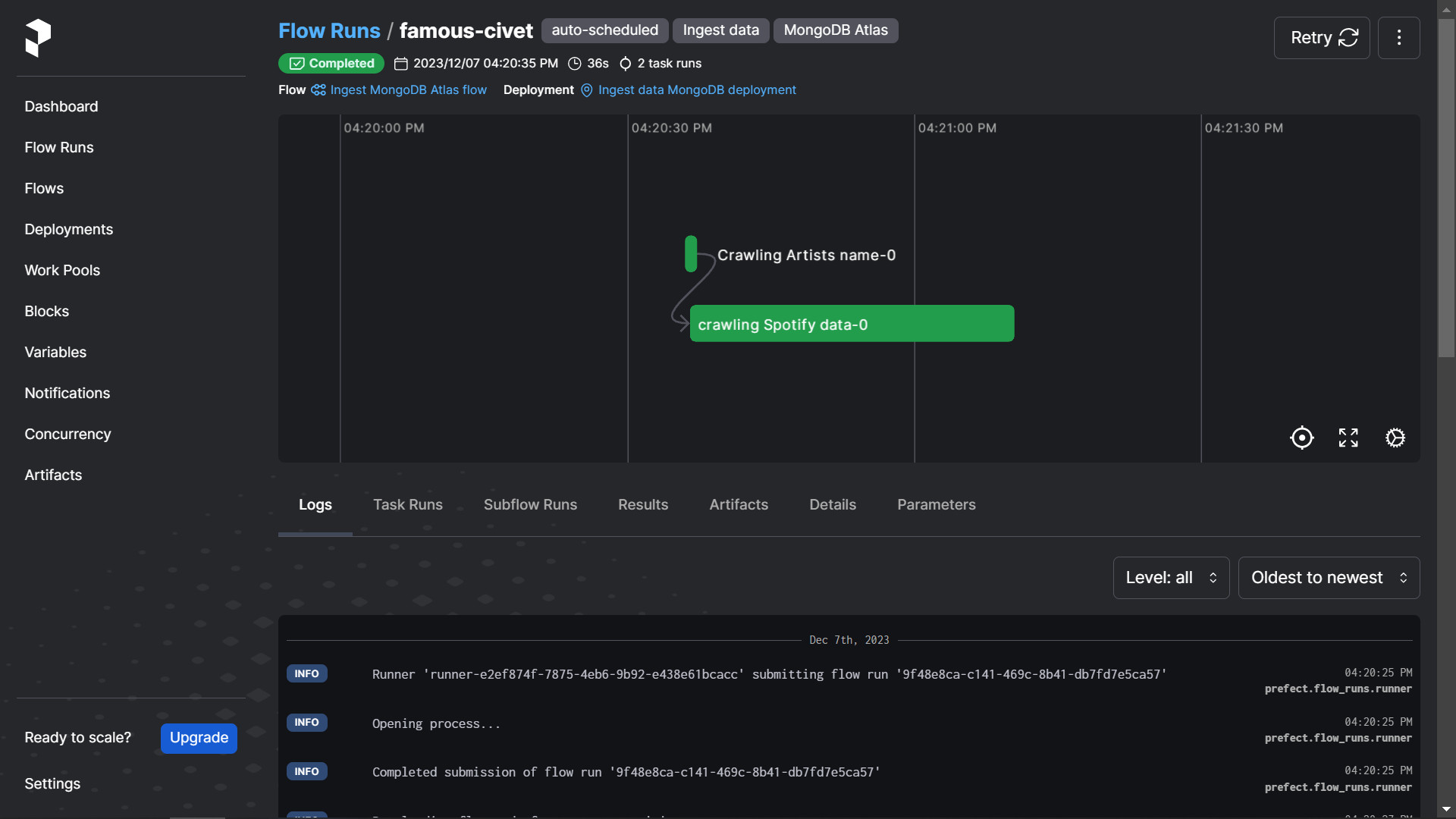
artists.txt để gọi spotify api qua mỗi batch
và dùng một file log.txt để đánh dấu vị trí index và số lượng nghệ sĩ đã cào thành côngPipeline 2
Đây là phần chính của project này và hầu hết các tác vụ xử lý sẽ thực hiện trong pipeline này. Pipeline này chính là một ELT (Extract - Load - Transform) data pipeline với nguồn raw là các collections từ MongoDB, sau đó sẽ được xử lý bằng spark và lưu trong hdfs. Ta đồng thời sẽ xây dựng một Medallion architecture ngay trong hdfs để phân vùng cho các loại data.
kiến trúc này được Databricks giới thiệu là một “data design pattern” dùng để tổ chức data trong lakehouse với mục tiêu là để cải thiện chất lượng data qua từng layer của kiến trúc này (bronze -> silver -> gold)
PySpark
Có lẽ bạn sẽ thắc mắc tại sao không thấy Apache Spark được set up. có 2 lý do:
- Tài nguyên hạn chế: đối với project hiện tại khi đã có quá nhiều services được chạy cùng lúc bởi docker containers, set up thêm spark cluster có thể sẽ quá tải và không đủ tài nguyên để deploy tất cả.
- Data nhỏ: thành thực thì số lượng data phải process không thực sự quá lớn (khoảng hơn 200k quan sát) thì việc sử dụng spark có thể sẽ lãng phí tài nguyên. tuy nhiên vì mục đích học tập và thực hiện project poc, ta sẽ sử dụng spark với local mode thay vì set up standardlone mode với cluster
local[*]: là chế độ local, chế độ này cho phép chạy mà không cần phải setup spark clusterspark://{master-node-name}:7077: chế độ standalone và ta sẽ kết nối với một spark clusteryarn-client: chế độ yarn-clientyarn-cluster: chế độ yarn-clustermesos://host:5050: mesos cluster
Và ở project này ta sẽ sử dụng local mode để tối ưu tài nguyên cũng như phù hợp với kích thước dataset. để tiện lợi cho việc tạo SparkSession, ta sẽ viết một sparkIO bằng contextlib
from pyspark.sql import SparkSession
from pyspark import SparkConf
from contextlib import contextmanager
@contextmanager
def SparkIO(conf: SparkConf = SparkConf()):
app_name = conf.get("spark.app.name")
master = conf.get("spark.master")
print(f'Create SparkSession app {app_name} with {master} mode')
spark = SparkSession.builder.config(conf=conf).getOrCreate()
try:
yield spark
except Exception:
raise Exception
finally:
print(f'Stop SparkSession app {app_name}')
spark.stop()điều này giúp đơn giản hóa việc tạo sparksession và tắt spark trở nên đơn giản và tránh thiếu sót
Ta cũng có thể làm tương tự cho việc kết nối với mongodb bằng cách viết một mongodb_io
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
from contextlib import contextmanager
import os
@contextmanager
def MongodbIO():
user = os.getenv("MONGODB_USER")
password = os.getenv("MONGODB_PASSWORD")
cluster = os.getenv("MONGODB_SRV")
cluster = cluster.split("//")[-1]
uri = f"mongodb+srv://{user}:{password}@{cluster}/?retryWrites=true&w=majority"
try:
client = MongoClient(uri)
print(f"MongoDB Connected")
yield client
except ConnectionFailure:
print(f"Failed to connect with MongoDB")
raise ConnectionFailure
finally:
print("Close connection to MongoDB")
client.close()Data Processing
ta sẽ xây dựng hdfs theo kiến trúc meddalion bằng cách chia data quality thành cách vùng (hay directory):
- Bronze layer: dùng để chỉ lưu raw data
- Silver layer: lưu data đã xử lý một phần (xử lý kiểu dữ liệu, xử lý kiểu array và các cấu trúc lồng phức tạp) từ Bronze Layer
- Gold layer: lưu data đã được làm sạch sau khi chuẩn hóa dữ liệu và làm sạch các bảng mới từ Silver Layer
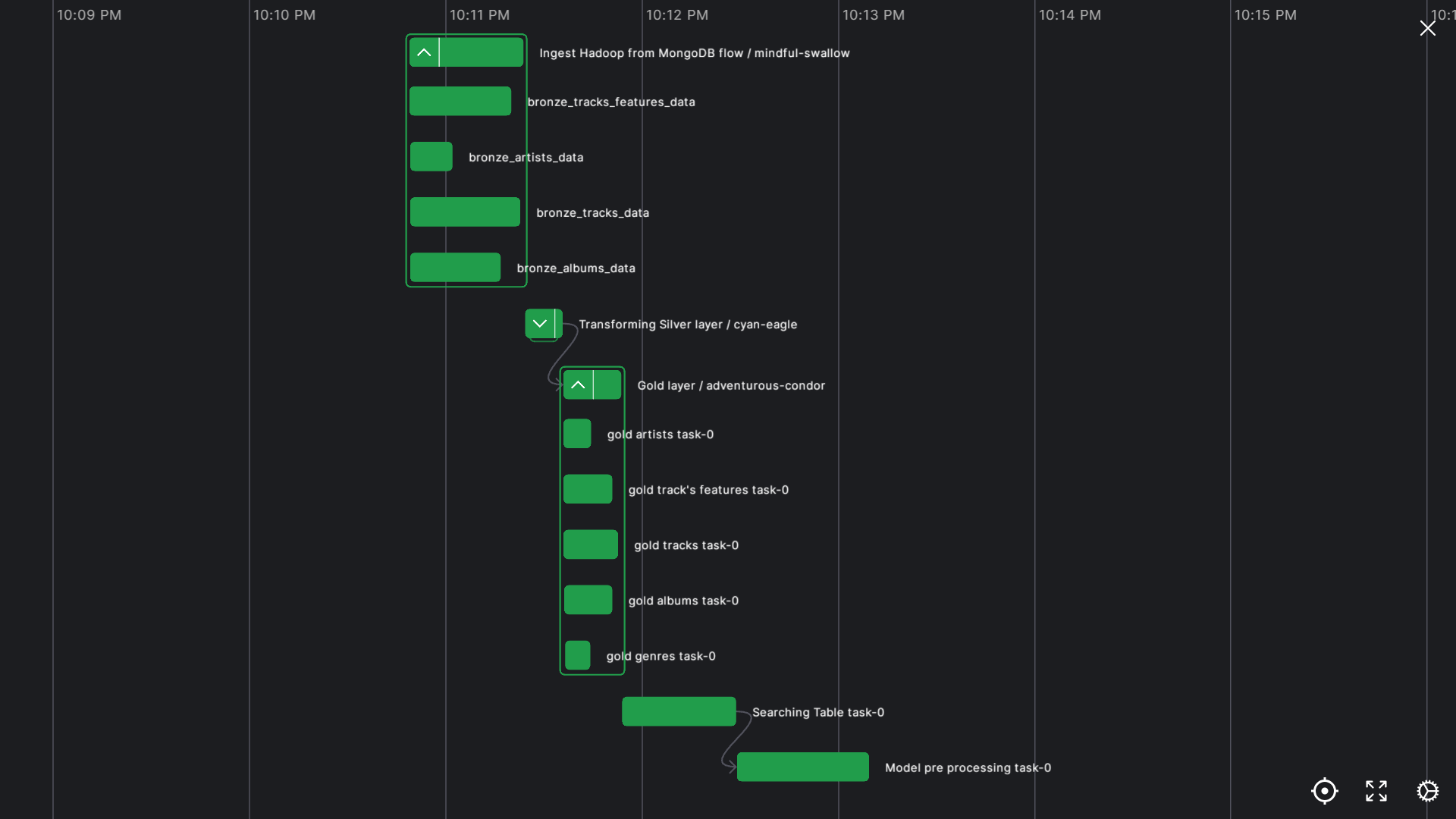
Analytic layer
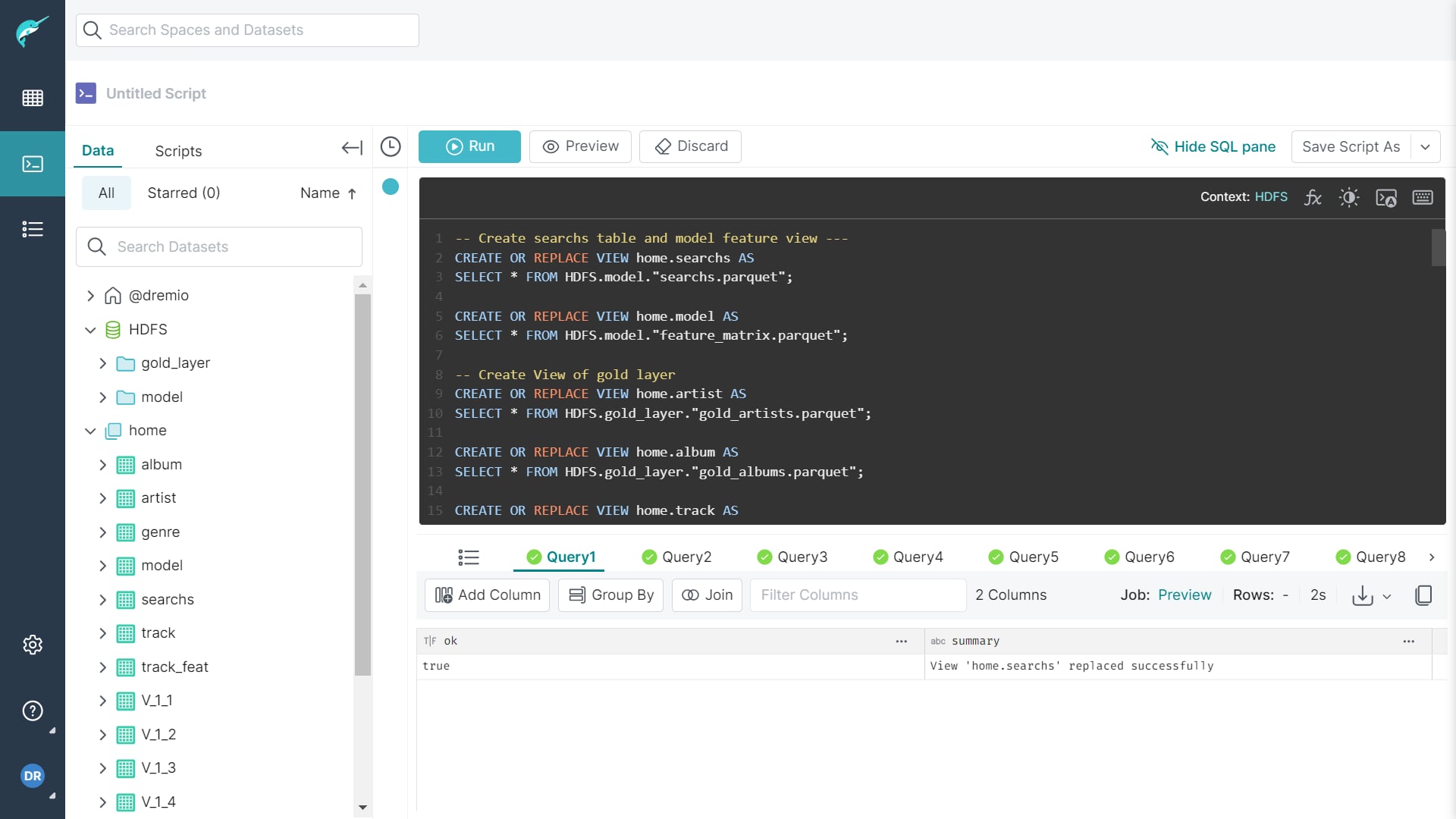
Như đã setup từ trước, ta sẽ sử dụng dremio như một analytic layer để có thể phân tích trên data sạch ở gold layer trong HDFS. Việc đơn giản là ta chỉ cần kết nối dremio đến HDFS qua dremio UI ở localhost:9047 và sau đó format file .parquet ở thư mục gold_layer và ta có thể viết các câu lệnh sql query để bắt đầu phân tích được rồi
Machine learning and Dashboard
Đến đây có thể coi như là kết thúc phần việc của một data engineer, ta sẽ bắt đầu các tasks của một data scientist và data analyst trong việc xây dựng mô hình máy học và xây dựng report.
K-Nearest Neighbors (KNN)
Ta sẽ xây dựng một mô hình có thể gợi ý nhạc dựa trên độ giống nhau giữa các features của những bản nhạc như: độ lớn, giai điệu, thể loại, tempo, mức độ sôi động,… Để làm được việc đó ta sẽ sử dụng một mô hình có thể đưa ra được top k các record khác nhau từ danh sách hàng trăm nghìn bài hát. Đó là KNN
KNN là một mô hình học máy đơn giản giúp ta tìm được top những điểm data gần nhất với vị trí data point đầu vào dựa trên khoảng cách của chúng trong không gian vector. Similarity Metric lần này ta sử dụng sẽ là độ tương tự consine hay consine similarity
$$ S_C(A,B) = cos(\theta) = \frac{A \cdot B}{\Vert A\Vert \Vert B \Vert} = \frac{\sum^n_{i=1}A_iB_i}{\sqrt{\sum^n_{i=1}A^2} \cdot \sqrt{\sum^n_{i=1}B^2} } $$
Ta sẽ xây dựng một mô hình gợi ý top k các bài hát giống nhất với bài hát lựa chọn như sau:
class SongRecommendationSystem:
def __init__(self, client, options):
self.client = client
self.options = options
self.knn_model = NearestNeighbors(metric='cosine')
def fit(self, table_name):
matrix_table = self._get_table(table_name).values
self.knn_model.fit(matrix_table)
def _get_table(self, table_name):
sql = f"select * from {table_name}"
return self.client.query(sql, self.options)
def recommend_songs(self, track_name: str, table_name='home.searchs', num_recommendations=5):
song_library = self._get_table(table_name).reset_index(drop=True)
if track_name not in song_library['track_name'].values:
print(f'Track "{track_name}" not found in the dataset.')
return None
features_matrix = self._get_table('home.model')
track_index = song_library.index[song_library['track_name'] == track_name].tolist()[0]
_, indices = self.knn_model.kneighbors([features_matrix.iloc[track_index]], n_neighbors=num_recommendations + 1)
return song_library.loc[indices[0][1:], :]Khi thử tìm các bài hát giống với “Something Just Like This” (có vẻ cũng chưa tốt lắm 😂)

PowerBI Dashboard
Khi có rất nhiều data sạch, điều tiếp theo ta có thể nghĩ đến chính là làm sao thấy được nhiều insight giá trị nhất từ data đó. Đây là lúc ta có thể dùng PowerBI để xây dựng Dashboard từ Dremio
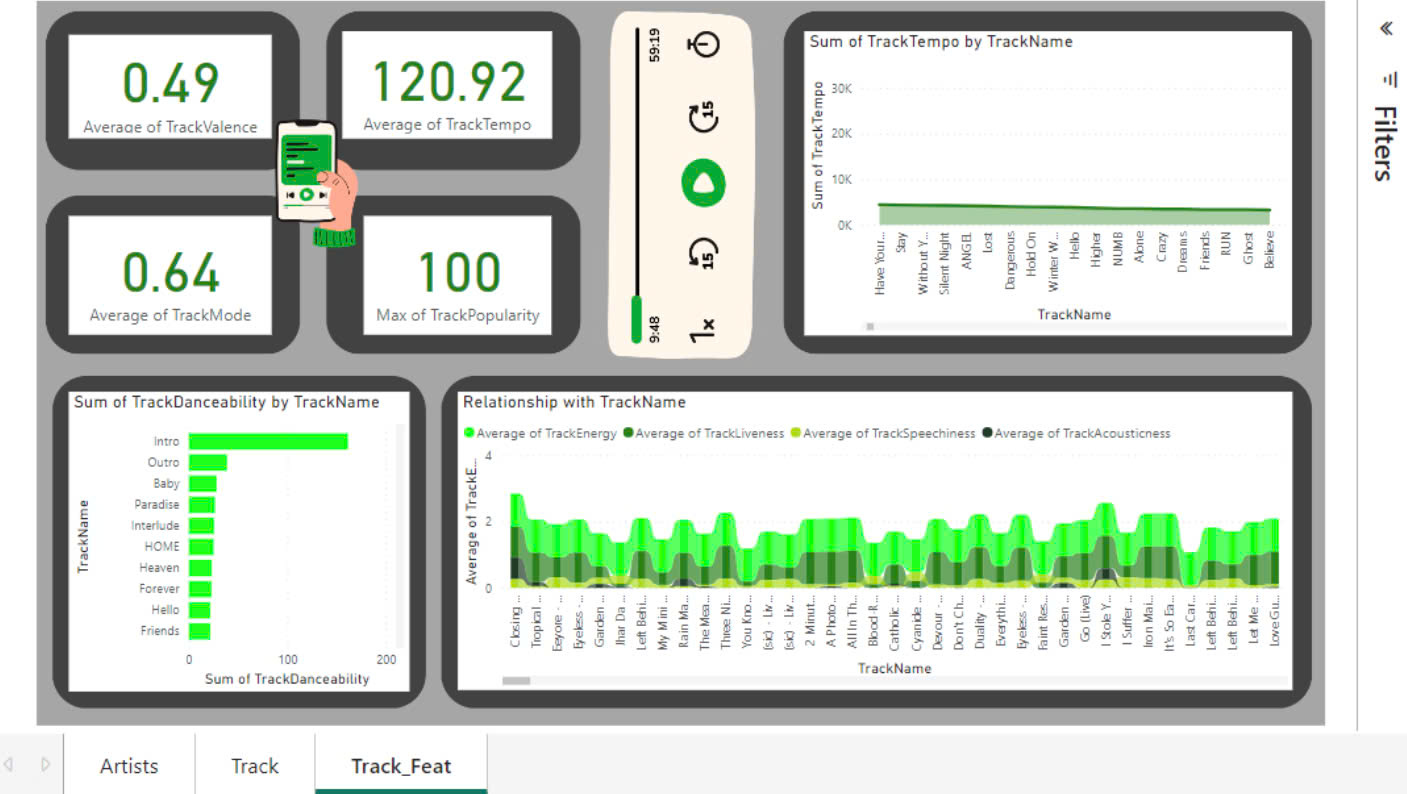
Application
Cuối cùng, ta có thể xây dựng một ứng dụng đơn giản để ứng dụng mô hình machine learning cũng như như tích hợp Dashboard vào trong ứng dụng này như một portal toàn diện. Ta sẽ sử dụng Streamlit để xây dựng một web app đơn giản
Project Demo
Final Thoughts
Project chỉ mang tính chất học tập, do đó độ lớn của data hay một số kiến trúc set up có thể chưa hoàn chỉnh. Tuy nhiên đây vẫn là một cột mốc đáng nhớ trong hành trình học tập của OG. Hy vọng nó sẽ giúp ích cho các bạn tham khảo 😄
-Meww-
Related
Football ETL Analysis
A Data Engineer project building pipeline to analyze football data
Read more...