Stock analysis
Source
Hello! OG đây. Ở project lần này mình sẽ phân tích gia trị cổ phiếu phái sinh VN30 Index bằng cách sử dụng PCA và K-means. Xin vô cùng cảm ơn sự đóng góp của 5 thành viên team OG và thầy Minh Mẫn và thầy Hoàng Đức đã tận tình hướng dẫn để team có thể hoàn thành đồ án một cách tốt nhất.
Rồi bây giờ gét gô thooiii 😄
Intro
Stock Analysis hay còn gọi là Market Analysis đề cập đến phương pháp mà nhà đầu tư hoặc nhà giao dịch sử dụng để đánh giá và điều tra một công cụ giao dịch cụ thể, lĩnh vực đầu tư hoặc toàn bộ thị trường chứng khoán. Không những thế, nó liên quan đến việc nghiên cứu dữ liệu thị trường trong quá khứ và hiện tại và tạo ra một phương pháp để chọn cổ phiếu phù hợp để giao dịch. Các nhà đầu tư sẽ đưa ra quyết định mua hoặc bán dựa trên thông tin phân tích chứng khoán.
Trong project này ta sẽ phân tích, trực quan hóa bộ dữ liệu giả định được cung cấp bởi khách hàng để đánh giá thị trường chứng khoán trong khoảng thời gian 1 tháng của 30 công ty thuộc VN30
Dưới đây là tóm tắt sơ lược từng bước để xử lý và phân tích:
- EDA (Exploratory Data Analysis)
- Data Preprocessing
- PCA (Principle Component Analysis)
- K-Means Clustering
- Data Analysis
- References (chi tiết trong notebook ở github)
Source: df_merged.pkl
Raw data là dữ liệu bảng giá cổ phiếu của 30 công ty thuộc VN30 Index + 1 trường giá phái sinh trong 1 tháng
Exploratory Data Analysis
Đây là bước đầu tiên, chúng ta sẽ cùng nhau tìm hiểu sơ lược raw data cũng như tìm hiểu cái nhìn tổng quát về dữ liệu ta sắp phải phân tích để từ đó có cách tiền xử lý phù hợp. Làm gì thì làm cứ phải import packages để đọc data cái đã
Data Acquistion
Ta sẽ import một số packages quen thuộc để đọc file df_merged.pkl
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_pickle('https://github.com/PhongHuynh0394/My-respository/blob/main/df_merged.pkl?raw=true')
# Check the data type
type(data) # --> listData nhận được từ pickle file là một list, bây giờ ta sẽ tìm kiếm cái nhìn tổng quan về dữ liệu này
A Brief View
- Dữ liệu lưu ở pickle là một list chứa 23 dataframe (df)
- Mỗi df có index theo datetime (nghĩa là đây là loại dữ liệu thuộc timeseries)
- Các columns lần lượt là từng mã cổ phiếu, chứa khối lượng/ giá của các lệnh mua/bán sát với lệnh khớp I và khối lượng của các lệnh mua/bán sát với giá khớp lệnh II
print('So luong df:', len(data)) # --> So luong df: 23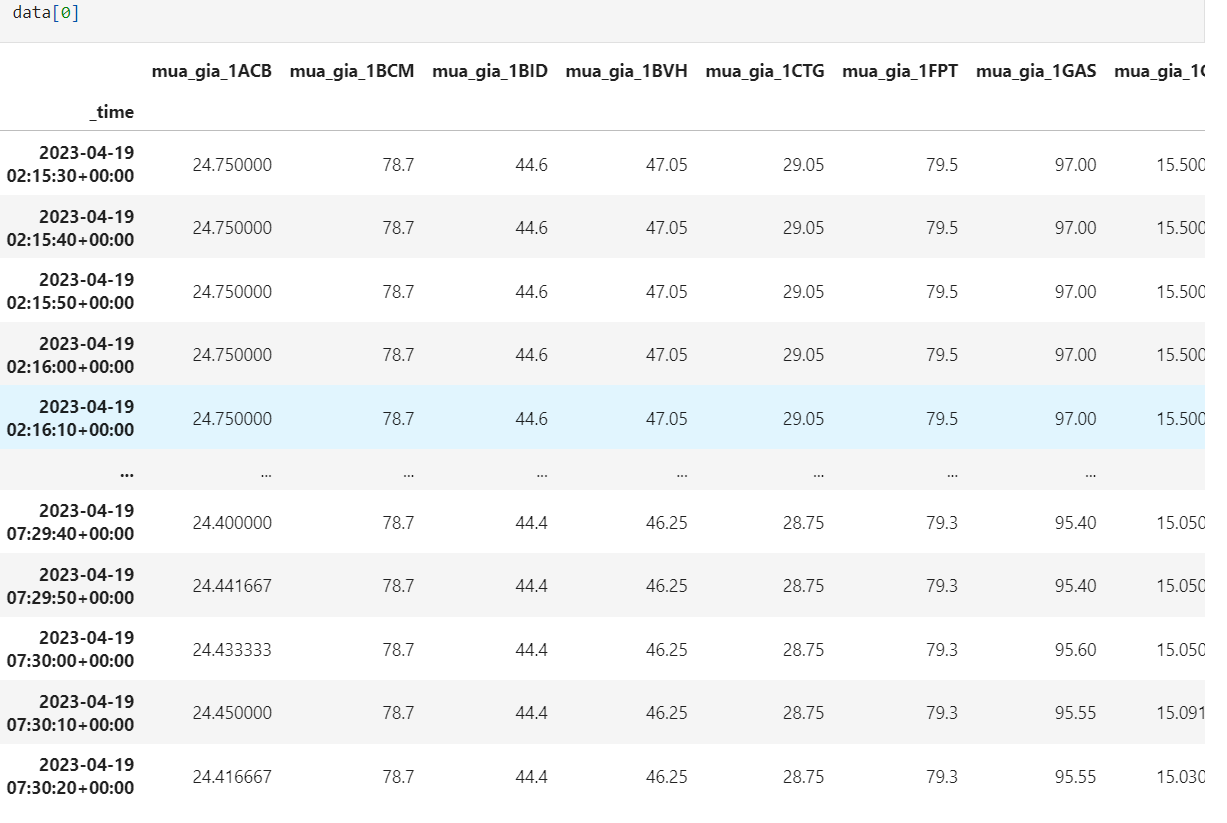
Thời gian thu thập được cập nhật với chu kì là 10 giây bắt đầu từ ngày 20 tháng 3 đến ngày 19 tháng 4, từ 2 giờ 15 đến 7 giờ 30 mỗi ngày. Nhưng có một số ngày bị miss trong bộ dữ liệu này (Chi tiết hơn trong notebook ở source code)
Cùng xem qua về số lượng observations của mỗi bảng
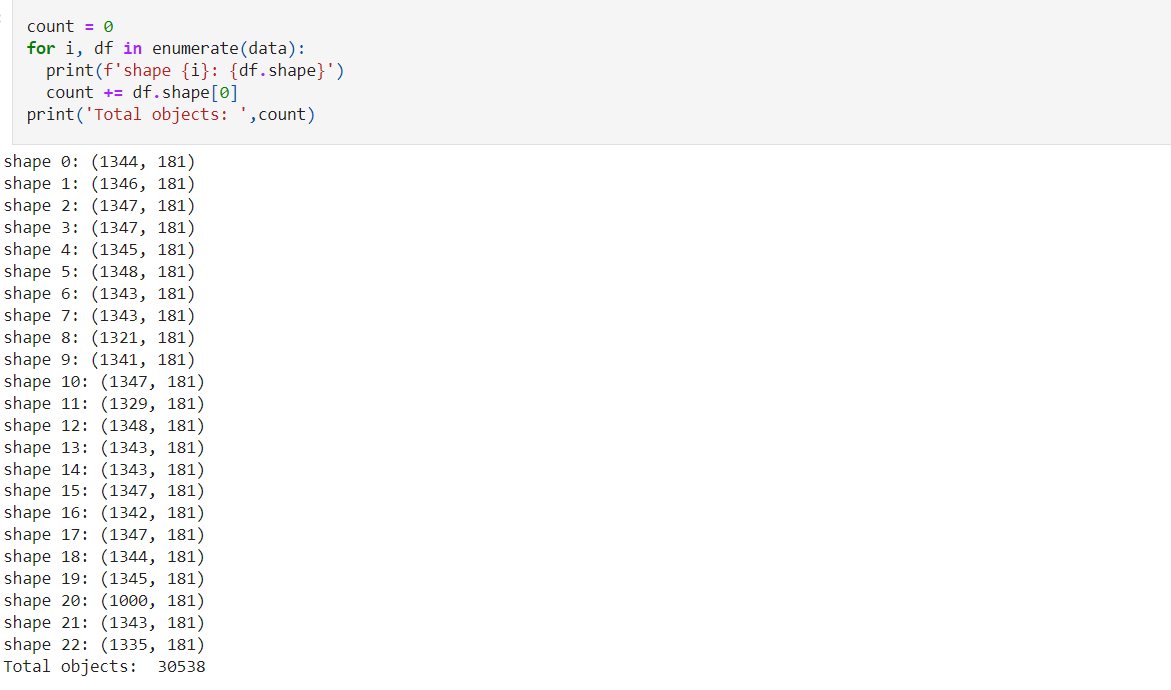 Tổng cộng ta có 181 fields và mỗi bảng khoảng 1345 observations (tổng cộng 30538 quan sát). Cũng khá nhiều phải không nào. Ta sẽ cùng tiền xử lý chúng nào
Tổng cộng ta có 181 fields và mỗi bảng khoảng 1345 observations (tổng cộng 30538 quan sát). Cũng khá nhiều phải không nào. Ta sẽ cùng tiền xử lý chúng nào
Data Preprocessing
Sau khi đã biết khái quát raw data, ta sẽ cần phải tiền xử lý những dữ liệu thô này trước khi có thể áp dụng các mô hình máy học hoặc giảm chiều dữ liệu
Data Cleaning
Hãy sử dụng method describe() của pandas để có cái nhìn sơ bộ nhất về df của chúng ta
data[0].describe()Đầu tiên, ta sẽ drop duplicate và định dạng lại index thời gian
market = pd.DataFrame(columns=data[0].columns.to_list()) #create empty df
# Data cleaning
for _, df in enumerate(data):
df.drop_duplicates()
cols = df.columns.to_list()
#convert/ replace 0
for col in cols:
df[col] = pd.to_numeric(df[col], errors='coerce')
# #missing handling
df.fillna(0, inplace=True)
market = pd.concat([market,df]).copy() #concat all clean df into market
#datetime format
market.reset_index(inplace=True)
market = market.rename(columns={'index': 'datetime'})
market['datetime'] = market['datetime'].dt.strftime('%Y-%m-%d %H:%M:%S')
market['datetime'] = pd.to_datetime(market['datetime'])
market = market.sort_values("datetime", ascending=True)
market.set_index('datetime', inplace=True)Kế tiếp hãy xử lý missing value bằng phương pháp nội suy (interpolation) với method padding, và sau đó sẽ dùng backfill
Đây là phương pháp ước tính giá trị của các điểm dữ liệu chưa biết trong phạm vi của một tập hợp rời rạc chứa một số điểm dữ liệu đã biết. Nghe có vẻ lằng nhằng, đơn giản là thế này:
- .interpolate(method=‘pad’): fill null values bằng giá trị liền kề nó lần lượt từ trên xuống (nó giống như
ffill()) - .fillna(method=‘backfill’): Đây là phương pháp ngược lại bên trên, fill null bằng giá trị liền kề từ dưới lên
Có rất nhiều phương pháp nội suy như linear (default) hay polynomial,… Nhưng OG chọn padding và backfill vì
2 phương pháp này có thể giữ cho data missing ở giá trị sát nhất với giá trị thực gần nhất và giúp cho kết quả sau khi fill sát với thực tế nhất.
Ngoài ra 2 phương pháp này có thể fill được vị trí đầu và cuối cùng một cách hiệu quả.
def handle_null(X: pd.DataFrame) -> pd.DataFrame:
'''
handle missing value
'''
for col in X.columns.to_list():
X[col].interpolate(method='pad', inplace=True)
X[col].fillna(method='backfill', inplace=True)
return XData transforming
OG nhận thấy rằng với các trường data hiện tại chưa thực sự giúp ích quá nhiều trong việc phân tích sau này (giá mua/bán và số lượng mua/bán + giá phái sinh (label) )
Do đó OG cần một dataframe mới với các trường mới có nhiều giá trị phân tích hơn:
- gttb_ (Giá trị trung bình): là column mới được tính trên bình quân giá cả mua vào, bán ra của từng cổ phiếu được giao dịch THÀNH CÔNG trên thị trường.
- total_ban & total_mua (Tổng bán/mua khối lượng 1): là column mới để tính tổng giá bán khối lượng 1 cũng như mua khối lượng 1 của từng cố phiếu được giao dịch trên thị trường.
- Gia_KL: sao chép giá khối lượng của từng mã cổ phiếu từ bộ dữ liệu ban đầu. (label)
- Cài đặt lại index thời gian: group by các time-series theo phút.
def transform_raw(market: pd.DataFrame) -> pd.DataFrame:
# split stock name
name = [col.split('_1')[-1] for col in market.columns.to_list() if 'mua_gia_1' in col]
new_df = pd.DataFrame()
for i in name:
# calculate gttb (mean)
new_df[f'gttb_{i}'] = ((market[f'mua_gia_1{i}'] * market[f'mua_kl_1{i}']
+ market[f'ban_gia_1{i}'] * market[f'ban_kl_1{i}'])
/(market[f'mua_kl_1{i}'] + market[f'ban_kl_1{i}'])).copy()
# get ban_kl and mua_kl
new_df[f'total_ban_{i}'] = market[f'ban_kl_1{i}'].copy()
new_df[f'total_mua_{i}'] = market[f'mua_kl_1{i}'].copy()
# get Gia KL
new_df['Gia KL'] = market['Gia KL'].copy()
new_df.set_index(market.index, inplace=True)
gttb = [col for col in new_df.columns.to_list() if 'gttb' in col] + ['Gia KL']
mua_ban = [col for col in new_df.columns.to_list() if col not in gttb]
# Group by minute
result = new_df[gttb].groupby([new_df.index.date, new_df.index.hour, new_df.index.minute]).mean()
result = pd.concat([result,new_df[mua_ban].groupby([new_df.index.date,
new_df.index.hour,
new_df.index.minute
]).sum()],axis=1)
#Set index in minute
index = pd.to_datetime([f"{d} {h}:{m}:00" for (d, h, m) in result.index])
result.index = index
#handle missing value
result = handle_null(result)
return resultRồi giờ transform rồi kiểm tra lại số lượng quan sát ở bảng mới thôi
# Check the length of new data
len(new_market) # --> 5154Với kết quả mới, chỉ còn lại 5154 quan sát mà thôi, khi rút lại một số lượng quan sát lớn như vậy, ta sẽ phải chấp nhận rủi ro mất đi nhiều thông tin về dữ liệu mà cụ thể là dữ liệu theo giây (cứ 10 giây cập nhật). Nhưng đổi lại, data sẽ cô động hơn và bớt nhiễu vì với sự biến đổi của thị trường trong cả 1 tháng, sự thay đổi của các trường trong mỗi 10 giây là quá nhỏ và không đáng kể.
Data Scaling
Sau khi có bộ dataframe mới tốt hơn và sạch sẽ, bước kế tiếp sẽ là scale lại dữ liệu về một chuẩn để tăng hiệu quả của các thuật toán học máy
Có một số phương pháp scale data như: Standardization, Normalization,…
Ở project này, OG sẽ dùng phương pháp Normalization để scale data. Phương pháp chuẩn hóa này đưa tỷ lệ dữ liệu từ phạm vi ban đầu về chuẩn phạm vi từ 0 đến 1, giá trị được normalize theo công thức sau:
$$ x’ = \frac{x - min}{max - min} $$ Với $x$ là giá trị cần được chuẩn hóa, $max$ và $min$ là lần lượt là giá trị lớn nhất và nhỏ nhất trong tất cả các observations của feature trong tập dữ liệu.
Ta sẽ dùng MinMaxScaler của scikit-learn trong tác vụ này.
from sklearn.preprocessing import MinMaxScaler
# Normalization data using libraries
min_max = MinMaxScaler()
X = new_market.values
X_std = min_max.fit_transform(X)
print('Data after scaling: ')
X_std
# array([[9.10048201e-01, 9.43990665e-01, 9.59215952e-01, ...,
# 1.31664615e-02, 1.45711006e-02, 2.90267046e-03],
# [9.14492108e-01, 9.61493582e-01, 9.57989455e-01, ...,
# 1.42007963e-02, 1.10109072e-04, 3.64335188e-03],
# [9.12286536e-01, 9.57992999e-01, 9.56950233e-01, ...,
# 3.58702686e-03, 1.43141794e-03, 4.40405173e-04],
# ...,
# [9.23665190e-01, 9.04317386e-01, 8.96622210e-01, ...,
# 1.22024151e-01, 3.04635100e-03, 2.10293470e-02],
# [9.24218272e-01, 8.89565349e-01, 8.97159958e-01, ...,
# 1.05691866e-02, 1.13779375e-03, 2.88265204e-02],
# [9.28532923e-01, 9.04317386e-01, 8.98196897e-01, ...,
# 8.84087818e-03, 3.67030241e-04, 7.79383700e-03]]Như vậy là đã chuẩn bị hoàn tất cho bước tiếp theo rồi. Chúng ta sẽ bước vào thuật toán chính đầu tiên trong project này.
Principle Component Analysis (PCA)
Chúng ta đã đi qua việc tiền xử lý dài ngoằn từ cleaning, transforming đến scaling. Vậy câu hỏi là: dữ liệu đã sẵn sàng để áp dụng cho các mô hình máy học hay chưa ?
Câu trả lời cho trường hợp này là: Chưa. Tại sao vậy ? Bởi vì tập dữ liệu của chúng ta có quá nhiều features
Hiện tại có thể thấy cleaning data của chúng ta có 91 features:
- gttb_(cổ phiếu): 30 cột giá trị trung bình giao dịch của 30 cổ phiếu trong 1 phút
- total_ban_(cổ phiếu): 30 cột tổng khối lượng bán của 30 cổ phiếu trong 1 phút
- total_mua_(cổ phiếu): 30 cột tổng khối lượng mua của 30 cổ phiếu trong 1 phút
- Gia_KL: 1 cột giá phái sinh VN30 Index (label)
Với số lượng feature lớn như vậy, sẽ vô cùng kém hiệu quả nếu ngay lập tức sử dụng train cho các mô hình machine learning. Giải pháp ở đây chính là ta sẽ giảm chiều dữ liệu xuống mức vừa đạt hiệu năng tốt khi training mà cũng không làm mất quá nhiều thông tin của dữ liệu.
Vâng đúng vậy, phương pháp OG muốn giới thiệu chính là PCA hay còn được biết với tên việt hóa là Phân tích thành phần chính. Mục tiêu của phương pháp này
là đưa bộ dữ liệu ban đầu sang hệ tọa độ mới dựa trên các thành phần chính. Dữ liệu ở hệ tọa độ mới có ít chiều hơn nhưng vẫn giữ được nhiều nhất thông tin có thể,
từ đó giúp tăng tốc độ tính toán và giảm độ phức tạp mô hình hơn rất nhiều.
Ở phần này chúng ta sẽ sử dụng phương pháp này thông qua sự phân rã của ma trận hiệp phương sai (Eigen decomposition of covariance matrix)
EigenVector và EigenValue
Ma trận hiệp phương sai được định nghĩa là:
$$ S = \frac{1}{N}\hat{X}^T\hat{X} $$
Với $\hat{X} = X - \hat{x}1^T$ là zero-corrected data hay dữ liệu đã được chuẩn hoá.
Ta sẽ viết hàm get_eigenpairs() để tìm các vector riêng và giá trị riêng của ma trận hiệp phương sai:
$$ Su_i = \lambda_iu_i $$
Trong đó: các $(\lambda_i,u_i)$ là các cặp trị riêng (không âm) và vector riêng của ma trận hiệp phương sai $S$
Tại sao lại cần tìm các vector riêng và giá trị riêng của ma trận hiệp phương sai ? Việc sử dụng các giá trị riêng để đánh giá sự quan trọng của mỗi thành phần chính được tạo ra từ việc giảm chiều dữ liệu. Các giá trị riêng càng lớn thì thành phần chính tương ứng càng quan trọng. Các vector riêng tương ứng với các giá trị riêng này được sử dụng để xác định hướng của các thành phần chính.
- Giá trị riêng (Eigenvalues $\lambda_i$): Các hệ số được gắn với các vector riêng, cung cấp cho độ lớn của trục. Trong trường hợp này, chúng là thước đo hiệp phương sai của dữ liệu.
- Vector riêng (EigenVector $u_i$):Các vector (khác 0) không thay đổi hướng khi áp dụng bất kỳ phép biến đổi tuyến tính (linear transformation) nào, nó chỉ thay đổi theo hệ số vô hướng.
- Hàm sắp xếp các vector riêng (Sort eigenvalues): Bằng cách sắp xếp các vector riêng theo thứ tự của giá trị riêng, ta có thể chọn ra các vector riêng có giá trị riêng lớn nhất để xây dựng các thành phần chính của dữ liệu (đóng góp nhiều nhất vào việc giải thích sự biến thiên của dữ liệu). Các thành phần chính này có thể được sử dụng để tái cấu trúc dữ liệu ban đầu mà vẫn giữ được độ giống nhau của các điểm dữ liệu ban đầu.
def get_eigenpairs(X: np.array) -> list:
'''
Input: X: np.array (init matrix)
return eigenpairs containing eigenvalues and eigenvectors of covariance matrix
'''
# Covariance matrix
cov_mat = np.cov(X.T)
# Eigenvalues and Eigenvectors
evals, evecs = np.linalg.eigh(cov_mat)
# Sort eigenvalues
epairs = [(abs(eval), evec) for (eval, evec) in zip(evals, evecs.T)]
epairs = sorted(epairs, key = lambda pair: pair[0], reverse = True)
return epairsCumulative Sum of Components
Tính tổng tích lũy của các thành phần trong PCA (Cumulative Sum of Explained Variance) để xác định tổng phần trăm phương sai được giải thích bởi các thành phần được giữ lại trong mô hình PCA. $$ r_K = \frac{\sum^K_{i=1}\lambda_i}{\sum^D_{j=1}\lambda_j} $$ là lượng thông tin được giữ lại khi số chiều dữ liệu mới sau PCA là K.
- Hàm findNumVec() thực hiện việc lấy các giá trị riêng từ danh sách các eigenpairs và chuyển đổi chúng thành một mảng numpy. Sau đó, nó tính tổng tích lũy của các giá trị riêng, sử dụng hàm np.cumsum () chuẩn hóa tổng của chúng => cho ra một danh sách các giá trị (trong khoảng từ 0 đến 1) đại diện cho tỷ lệ phần trăm phương sai được giải thích bởi mỗi thành phần chính.
- Sau đó, hàm lặp qua danh sách tổng tích lũy và tìm chỉ mục của giá trị đầu tiên lớn hơn hoặc bằng tỷ lệ phần trăm phương sai mong muốn được giải thích. Chỉ số này đại diện cho số lượng thành phần chính cần thiết để giải thích tỷ lệ phần trăm phương sai đó, vì vậy hàm trả về giá trị này cộng với 1 (vì lập chỉ mục Python bắt đầu từ 0).
def findNumVec(eigenpairs: list, percent = 0.9):
'''
Find number of principal components (eigenvectors)
-> return the number of principal components when total accumulate >= percent
'''
# Get eigenvalues
eigenvals = [eigenval for (eigenval, _) in eigenpairs]
eigenvals = np.array(eigenvals)
# Cumulative sum and calculate percent
cumsum = np.cumsum(eigenvals)
cumsum /= cumsum[-1]
# Find number of principal components that accumulate >= percent
for i, val in enumerate(cumsum):
if val >= percent:
return i + 1Ta sẽ thử tìm xem số thành phần chính cần để giữ được 80% dữ liệu:
print(findNumVec(epairs, 0.8)) # --> 28Scree Chart
Ta sẽ vẽ một biểu đồ thể hiện quan hệ của số lượng thành phần chính và phần trăm phương sai giải thích tích lũy
def screeplot(eigenpairs):
'''
Scree plot
'''
fig, axes = plt.subplots(nrows = 2, ncols = 1, sharex = True)
eigenvals = [eigenval for (eigenval, _) in eigenpairs]
eigenvals = np.array(eigenvals)
cumsum = np.cumsum(eigenvals) # extracts the eigenvalues from the eigenpairs and calculates their cumulative sum
cumsum /= cumsum[-1]
name = [f'PCA {i}' for i in range(len(cumsum))]
# line plot
# the eigenvalues are plotted against the number of principal components
axes[0].plot(range(len(eigenvals)), eigenvals, marker = '.', color = 'b', label = 'Eigenvalue')
# the cumulative proportion of the variance explained by each component is plotted against the number of principal components
axes[1].plot(range(len(cumsum)), cumsum, marker = '.', color = 'green', label = 'Cumulative propotion')
# y axis label
axes[0].set_ylabel('Eigen values')
axes[1].set_ylabel('Cumulative explained variance')
# item legend
axes[0].legend()
axes[1].legend()
# grid
axes[0].grid()
axes[1].grid()
# title
fig.supxlabel('Number of components')
plt.tight_layout()
plt.show()
#print the cumsum of eigenvalues
print(pd.DataFrame(cumsum, columns = ['Cumulative total'], index = name))
result = {
str(i): f"PC {i+1} ({var:.1f}%)"
for i, var in enumerate(cumsum*100)
}
return result
pca_scree = screeplot(epairs)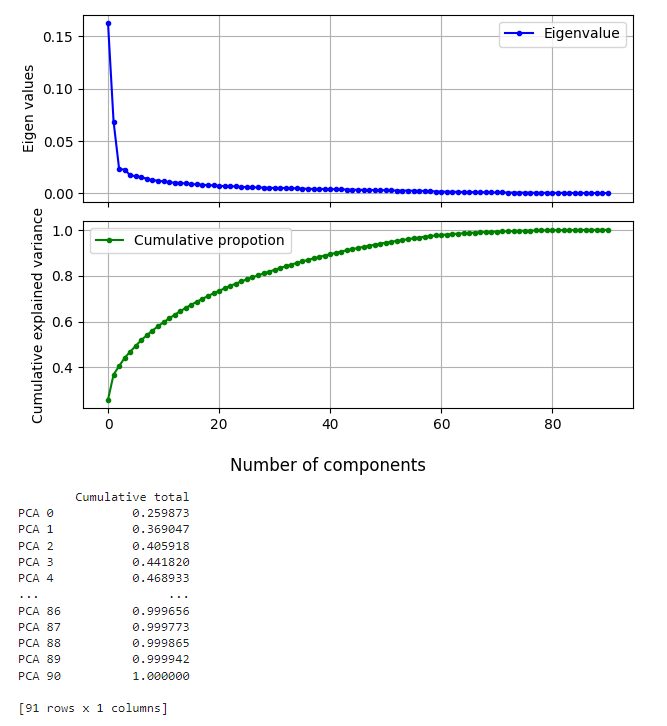
Đường của giá trị riêng màu xanh nước biển trên biểu đồ cho ta biết độ lớn của mỗi thành phần chính và tầm quan trọng của chúng trong giải thích sự biến thiên của dữ liệu. Nếu giá trị riêng của một thành phần chính là lớn, thì thành phần đó có tầm quan trọng cao trong việc giải thích sự biến thiên của dữ liệu.
Đường màu xanh lá thể hiện tổng tích lũy cho ta biết tổng phần trăm độ lớn của sự biến thiên của dữ liệu mà các thành phần chính có thể giải thích.
Visualize PCA
Bây giờ, ta sẽ thực hiện chiếu dữ liệu ban đầu đã chuẩn hóa $\hat{X}$ xuống không gian con tìm được và lấy ra ma trận các thành phần chính để tiếp tục công việc phân tích và xây dựng mô hình.
Hàm getPC() trả về một ma trận các thành phần chính từ ma trận ban đầu, dựa trên số lượng thành phần đã cho hoặc số lượng thành phần giữ được 80% dữ liệu (nếu num_components không được đưa ra).
Ma trận trọng số $W$ là ma trận chuyển đổi tuyến tính được sử dụng để chuyển đổi dữ liệu gốc vào không gian mới, trong đó mỗi thành phần chính được sắp xếp theo độ quan trọng giảm dần. Cụ thể, mỗi cột của ma trận $W$ là một vector riêng chuẩn hóa tương ứng với các giá trị riêng của ma trận hiệp phương sai $s$.
Thực hiện việc nhân ma trận $W$ với hoán vị của ma trận đã chuẩn hóa $\hat{X}$ (init_matrix). Ma trận kết quả sau đó tiếp tục được hoán vị để phù hợp với hình dạng ban đầu của init_matrix và trả về kết quả.
def getPC(eigenpairs, init_matrix, num_components = None):
'''
Return matrix of principal components from init_matrix
'''
# default num_components = number which to keep 80% data
if num_components is None:
num_components = findNumVec(eigenpairs, 0.8)
# extracts the eigen vectors corresponding to the top num_components eigenvalues from the eigenpairs list
eigenvecs = [eigenvec for (_, eigenvec) in eigenpairs[:num_components]]
W = np.array([e.T for e in eigenvecs]) # stacks the eigen vectors into a weight matrix W
return (W @ init_matrix.T).T
X_pca = getPC(epairs, X_std)Vậy là ta đã giảm được độ phức tạp cho bộ dữ liệu khá “nhọc nhằn” này. Hãy trực quan hóa lên biểu đồ để có một góc nhìn cụ thể và rõ ràng hơn.
Biểu đồ scatter plot sau khi PCA có thể giúp cho chúng ta nhìn thấy cách dữ liệu được phân bố trên các thành phần chính (principal components) và kiểm tra xem liệu chúng ta có thể tìm thấy các cluster hoặc pattern nào trong dữ liệu.
plt.scatter(X_pca[:,0], X_pca[:,1])
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('Visualizing data through PCA', fontsize=18)
plt.gca().set_aspect('equal', 'datalim')
plt.grid()
plt.show()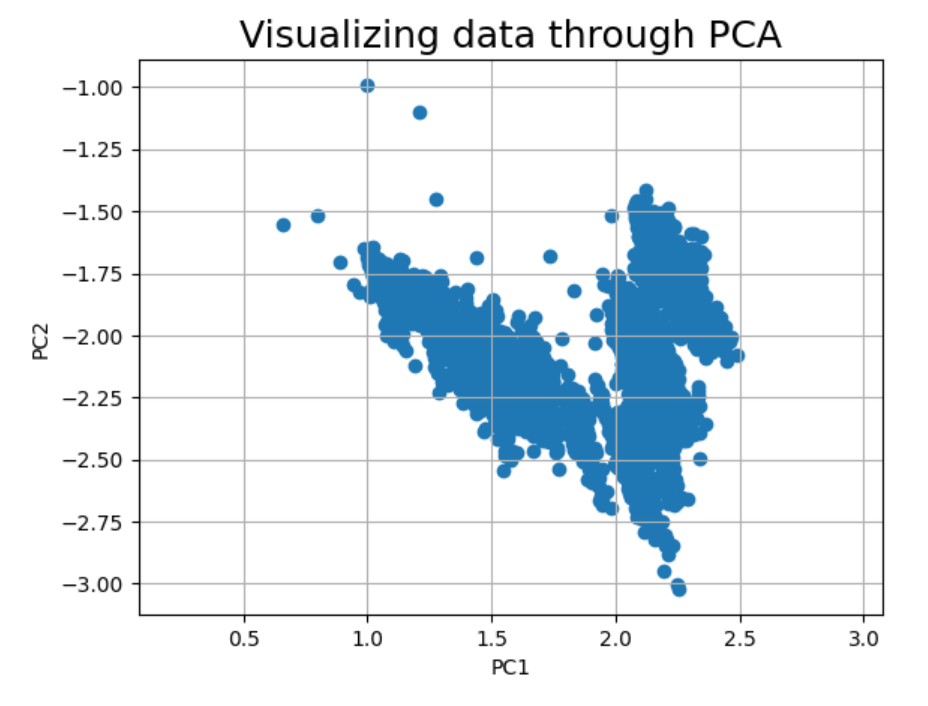
Okayy dựa vào biểu đồ trên, cũng có thể thấy là dữ liệu ở không gian mới đã phân tách khá rõ ràng rồi. Điều này nghĩa là phương pháp PCA đã
giảm số chiều của dữ liệu một cách hiệu quả. Bước tiếp theo chính là áp vào mô hình K-Means để phân cụm và tìm pattern. Chúng ta sẽ cùng chiến tiếp ở phần 2 nhé
To be Continue
Chúng ta đã thực hiện các bước tiền xử lý dữ liệu và sau đó là thực hiện PCA để giảm chiều dữ liệu một cách hiệu quả. Bài sau phần 2, OG sẽ thực hiện training mô hình K-means clustering và cuối cùng là phân tích dữ liệu chứng khoáng.
Đây là kiến thức tích góp từ nhiều nguồn và nghiên cứu của nhóm OG, tất nhiên không thể tránh khỏi sai sót. Hy vọng bài viết lần này thú vị và giúp bạn đọc thư giãn, tham khảo.
-Mew-
Related
Football ETL Analysis
A Data Engineer project building pipeline to analyze football data
Read more...
Spotify Analysis
Analyze data from Spotify platform utilizing the Spotify API and MongoDB, Apache Hadoop, Pyspark, Dremio and Power BI
Read more...